An Attentive Survey of Attention Models(2021)研读报告
论文标题:关于注意力模型的细心调研
如今注意力模型已经成为了神经网络中一个非常重要的概念,而且在多种应用领域中得到了广泛的研究。这篇调研针对注意力机制的发展提供了一个结构化、综合的概述。我们将现有的注意力技术分类。我们回顾了一些具有注意力模型的神经结构,并且讨论一些注意力模型已经发挥显著作用的应用。我们还描述了注意力机制是如何用来提升神经网络的可解释性的。最后我们讨论了一些未来的注意力机制的研究方向。这篇调研可以针对注意力机制提供一个简洁的介绍,并在实践人员开发应用时提供引导。
1 INTRODUCTION
注意力模型(AM)最早用于机器翻译,并为神经网络模型带来很大的优势。AM作为大量NLP应用中的一个基本部件,它已经变得非常出名。注意力机制背后的直觉(intuition)可以用人类生物系统解释。举个例子,我们的视觉处理系统倾向于把注意点放在图像的某些部位,同时忽略其他不相关的信息。类似的,在一些关于语言、视觉、听觉的问题中,输入的某些部分比其它部分更加重要(如图像描述问题,相较于其他区域,图像的某一个特定区域可能对于生成描述句的下一个词更加重要)。注意力模型通过动态的调整模型的注意力从而让模型只注意对完成任务有用的部分输入。下面是[Yang et al. 2016] 做的关于注意力机制在情感分类问题中的应用的例子。AM学习到在这五句话中,第一句和第三句对情感分析更有帮助。

对注意力进行建模发展迅速的三个原因:
- 是解决多任务最先进的模型。
- 为提升主任务性能提供了其它的优势。它被用于提升神将网络的可解释性(越来越多的人对影响人类生活的应用中的网络模型的公平性、问责制、透明度感兴趣)。
- 它们有助于克服递归神经网络RNN中的一些挑战,例如随着输入长度的增加性能下降,以及输入顺序不合理导致的计算效率低下。
文章的组织:我们的工作致力于为注意力建模提供一个简短但是综合的研究。在第二节我们用一个简单的回归模型来为你提供关于注意力的初步印象。在第三节我们简短的介绍了[Bahdanau et al. 2015]提出的AM和其他的注意力函数(attention function)。第四节我们介绍了我们的分类结果。第五节和第六节讨论了使用AM的关键神经结构并展示了一些广泛使用注意力机制的应用。最后在第七节我们解释了注意力如何促进理解神经网络的可解释性,并在第八节介绍了未来的研究方向。
相关的调研:目前已经有一些专门领域的关于注意力机制的研究。如:
- [Wang and Tax 2016] on cv
- [Lee et al. 2019] on graphs
- [Galassi et al. 2020] on nlp
2 ATTENTION BASICS
[Nadaraya 1964; Watson 1964]提出的回归模型可以帮助我们理解注意力机制。我们的数据样本有n个数据$\{(x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)\}$。我们想知道当给定一个x时其对应的y的预测值$\hat{y}$。一个朴素的估计器对于任何输入都会输出样本中$y_i$的平均值。Naradaya-Watson提出了一个更好的方法:使用$y_i$的加权平均数。$y_i$的权值为$x,x_i$之间的相关度。公式如下:
$\alpha$是一个衡量$x,x_i$关联程度的函数。对于$\alpha$的一个普遍的选择是使用高斯核。Naradaya-Watson表示这种估计器有两个特性:
- 一致性(consistency):数据样本量越大结果越好。
- 朴素性(simplicity):没有没用的参数。信息存储在样本数据中而不是在权重中。
往后推50年,深度模型中的注意力机制可以看作是上述公式的一种泛化,即权重函数是可以学习的。
3 ATTENTION MODEL
AM的第一次应用被[Bahdanau et al. 2015]用来解决一个sequence-to-sequence modeling
task。s2s Model含有一个编码器(encoder)和一个解码器(decoder),他们的隐藏状态分别为$h_i,s_i$。编码器获得输入$\{x_1,x_2,\dots,x_T\}$并输出T个具有固定长度的向量$\{h_1,h_2,\dots,h_T\}$。将$h_T$输入解码器,解码器会输出$\{y_1,y_2,\dots,y_{T’}\}$token by token。
上述模型有两个问题(挑战):
- 将所有输入压缩成一个具有固定长度的向量会造成信息丢失。
- 无法对输入和输出序列之间的排列进行建模
也就是说解码器在输出每个token时无法有选择的使用输入。
核心思想:使用注意力权重来决定哪些输入对下一个输出更重要。
注意力的使用方法:如下图(b)。在解码器的第j个时间步,模型结构中的注意力模块负责自动生成注意力权重$\alpha_{ij}$。用这个权重表示$s_{j-1},h_i$直间的关联度。接着这些权重会通过$c_j=\sum_{i=1}^{T}\alpha_{ij}h_i$生成contex vector c。c会输入到解码器的下一个时间步。通过生成c,解码器就可以获得整个输入信息同时只把”注意力”放在输入的某部分。这种方法提升了算法的性能和输出的质量。Table 1 是这种注意力机制的数学表达。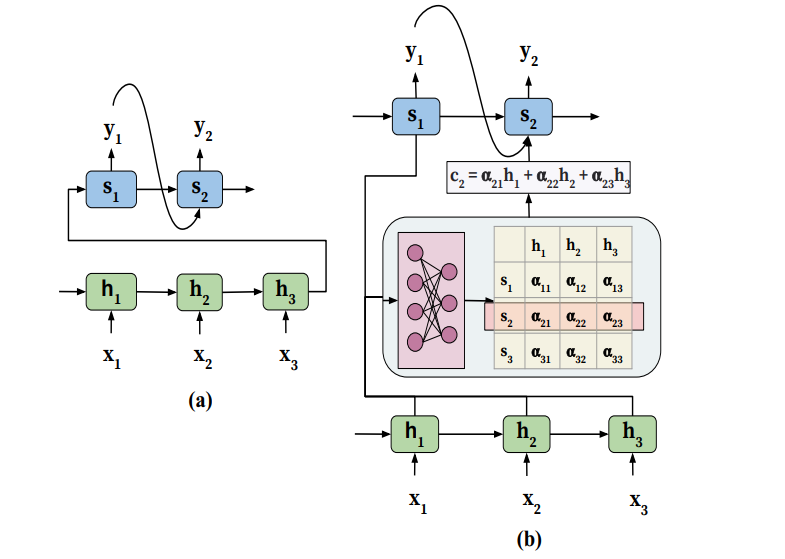

学习注意力权重: 注意力权重的学习可以通过引入一个前馈神经网络来完成。这个前馈神经网络作为一个函数,它的的输入为$h_i,s_{j-1}$。这个函数叫做alignment funcion(table 1 中用a表示),它会对$h_i,s_{j-1}$的相关度进行评估(有的资料把这个函数叫做评分函数scoring function)并输出评分$e_{ij}$。distribution function(table 1中用p表示)会把$e_{ij}$转化为注意力权重。当a,p是可微的函数时,这整个基于注意力的encoder-decoder模型就会成为一个大的可微函数,并且可以一同训练。
泛化的AM:AM可以看作是一种映射。这个映射会根据query q将keys K映射为权重$\alpha$。其中keys即为编码器的隐藏状态$\{h_1,h_2,\dots,h_T\}$,q即为$s_{j-1}$。注意力模型表示如下:
通常keys和values是一一对应的。在[Bahdanau et al. 2015]提出的模型中,$h_i = v_i = k_i$。通过上面的回归的例子来理解这个公式,输入x为query,$v_i$为$y_i$,$k_i$为$x_i$。
Alignment functions(排列函数?):
对于key和query在相同向量空间的:
- 余弦相似度或者点积(dot product)
- 考虑到不同的表示长度,scaled dot product使用表示向量的长度来归一化点积。
对于key和query在不同向量空间的:
- General alignment:引入可学习的转换矩阵将query映射到key的向量空间。
- Activated general alignment:添加一个非线性的激活层(hyperbolic tangent, rectifier linear unit, or scaled exponential linear unit. )
- Biased general alignment :不管query,通过添加偏置项(bias)直接学习一些key的全局重要性。
- [Choromanski et al. 2021] 展示了key和query可以通过generalized kernel function匹配,而不是点积。
key,query联合表示的: - concat alignment:keys和queries拼接到一起形成联合表示。
- Additive alignment:对key和query的贡献进行解耦。使得可以提前计算所有key的贡献而不用对每个query再计算一遍。降低了计算时间。
- deep alignment 使用了多层神经网络。
针对特定使用场景的: - Location-based alignment:忽略keys的内容,只使用它的位置信息。
- [Li et al. 2019a]提出当处理一组元素(如2-D patches for images 或者 1-D temporal
sequences),从属于该组的单个元素的表示中得出的特征(如平均数和标准差)可以作为alignment function的输入。

distribution function(分布函数):
- dense distribution:softmax,logistic sigmoid。输出可以看作概率,但会降低模型的可解释性,而且会对不可能的输出分配概率(This density is wasteful, making models less interpretable and assigning probability mass to many implausible outputs. )。
- sparse distribution:sparsemax和sparse entmax。通过只对少量可能的输出赋予概率从而产生sparse alignment。当大量元素之间是不相关时会非常有用。
- [Tay et al. 2019]提出一种分布函数。计算两个项——$thanh(\frac{qk_i^T}{\sqrt{d_k}}),sigmoid(\frac{G(qk_i^T)}{\sqrt{d_k}})$的乘积来形成准注意力(qusi-attention)。其中第一项控制向量的加或者减,第二项可以看作是控制删除不相关元素的门函数。
4 TAXONOMY OF ATTENTION
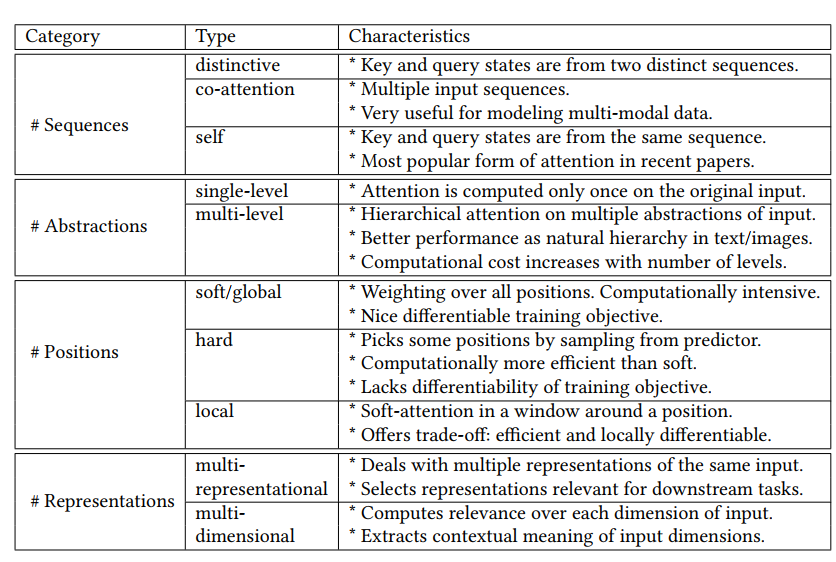
4.1 Number of sequences
- distinctive attention:输入和输出是独立的两个序列。上面考虑的全是这种情况。大部分情况应用于翻译 [Bahdanau et al. 2015]、图像描述[Xu et al. 2015]和语音识别[Chan et al. 2016]。
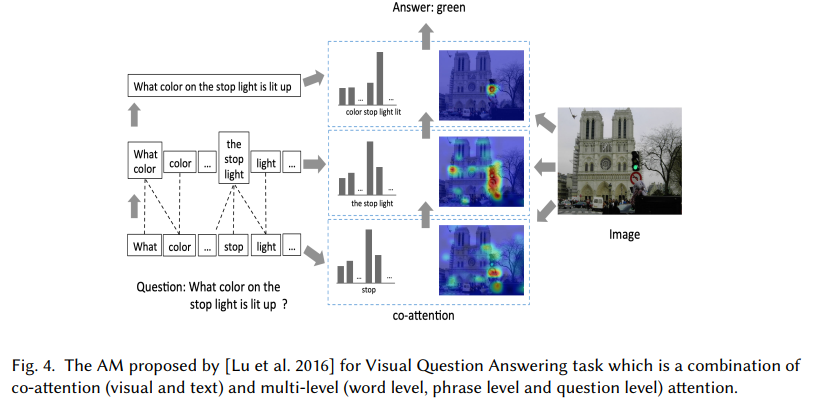
- co-attention:输入有多个序列,同时计算他们的注意力权重。[Lu et al. 2016]用它来做visual question answering。不仅提取图像中的重要信息a同样也要提取问题中的关键点b。a和b会互相影响。类似的[Yu et al. 2019] 也用它来做visual question answering task
- self-attention(inner attention)。每个输入序列都可以学习自身中相关的元素。即key和query在同一个序列中。
4.2 Number of abstraction levels
- single-level:只对原始输入添加注意力权重。
- multi-level:注意力模型的低层输出变为高层的输入(query)。再细分可以根据学习顺序分为自顶向下,自底向上两类。 [Yang et al. 2016]用“Hierarchical Attention Model”(HAM) 解决文档分类问题。这种多层模型可以从句子中找到关键词,从文档中找到关键句。上面提到的 [Lu et al. 2016]使用的co-attention也是多层模型(单词层,短语层,问题层),如下图。[Zhao and Zhang 2018]提出attention-via-attention,低层为字母高层为单词,并通过自顶向下的方式学习。
4.3 Number of positions
- soft attention:编码器输出的所有隐藏状态都要参与注意力的计算。方便反向传播但是会造成二次方的损失(quadratic computational cost)。
- hard attention:[Xu et al. 2015]提出通过范畴分布(multinoulli distribution)随机选取隐藏状态计算注意力权重。降低了计算损失但导致函数不可微,并且难以优化。Variational learning方法和 policy gradient 方法的提出可以帮助解决这些缺陷。
- local and global:[Luong et al. 2015b] 为机器翻译提出两种注意力模型:local、global。global类似soft attention模型。local介于soft和hard之间。local的关键想法是在输入序列中找到一个”注意点”(attention point),在这个点(位置)周围选择一个创建一个窗口,在窗口中建立局部soft attention模型。这个点(位置)可以认为设定(monotonic alignment) 或者通过学习得到(predictive alignment)。
4.4 Number of representations
- Single-representational AM:只使用输入序列的一种特征表示法。这是大多数应用使用的方法。但是在某些情况下不能满足下游任务。
- Multi-representational AM:通过多种特征表示来获取输入的不同方面的特征,然后使用注意力机制为不同的表示添加权重从而决定与这个任务最相关的表示法。[Kiela et al. 2018]、[Maharjan et al. 2018]、[Lin et al. 2017] 、 [Shen et al. 2018] 都做了类似的工作。
5 NETWORK ARCHITECTURES WITH ATTENTION
5.1 Encoder-Decoder
最早在 [Bahdanau et al. 2015]中提出。编码器把输入压缩到一个固定长度的向量,解码器再对这个向量进行处理。这种方式把输入输出进行解耦,这使得杂交encoder-decoder成为了可能。比如编码器用CNN,解码器用LSTM。对许多模型任务例如图像,视频描述、Visual Question Answering和语音识别有非常大的帮助。
但是并不是所有问题都可以的输入输出都是序列化的。Pointer Network [Vinyals et al. 2015]有如下的两个不同:
- 输出是离散的值,并且指向了输入序列的某个位置。
- 输出类别取决于输入的数量。
作者通过使用注意力权重来对每个时间步选择第i个输入符号的概率。这个方法可以用作离散优化问题(旅行商,排序)
5.2 Transformer
循环结构会序列化的处理输入,这导致计算效率下降。Transformer [Vaswani et al. 2017].通过使用自注意力机制来获得输入输出的全局依赖。作者展示了使用Transformer,即便不使用循环结构也可以在机器翻译任务中获得超强的并行处理能力,更短的训练时间和更高的准确度。
5.3 Memory Networks
类似Question Answering的应用需要拥有从事实数据库中学习的能力。网络的输入是知识数据库(knowledge dagabase)和一个问题(query)。在数据库中有些事实是与问题相关的但有些不是。在这种情况下就需要注意力来选择相关的事实。
5.4 Graph Attention Networks (GAT)
战略性略过
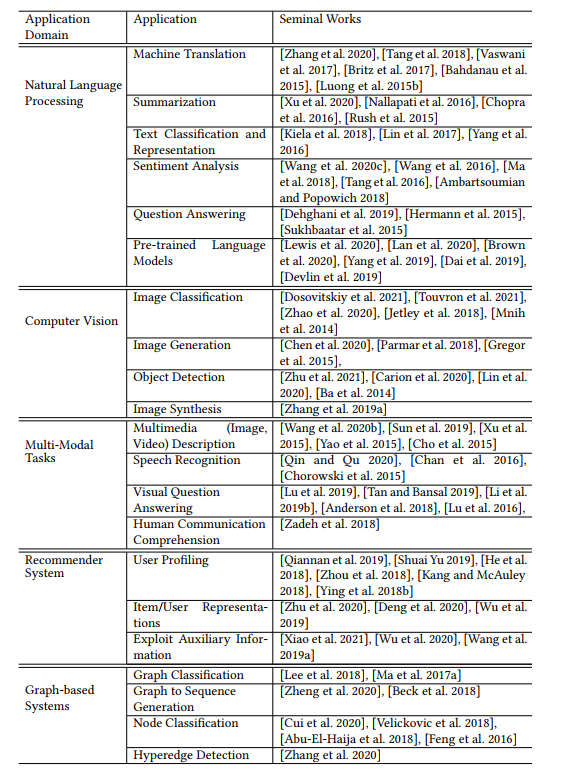
6 APPLICATIONS
7 ATTENTION FOR INTERPRETABILITY
越来越多的人关注AI模型的可解释性,而且这正是神经网络特别是深度学习网络所欠缺的。注意力机制可以帮助我们提升AI模型的可解释性。存在的一种假设是注意力权重的大小与对应输入部分与当前时间步下的输出的相关度有关。通过可视化输入输出对可以发现这种规律。
[Rush et al. 2015]展示了在(文本)总结问题中,AM可以在输出时把注意力放在输入的相关的单词上(下图a)。 [He et al. 2018]表示注意力可以用来识别用户的兴趣(下图b)。[Xu et al. 2015]通过可视化展示了图片摘要问题中对输出有很大影响的图形区域。
总结几种有趣的事实:
- [De-Arteaga et al. 2019] explored gender bias in occupation classification, and showed how the words getting more attention during classification task are often gendered.(没看懂,直接粘原文了)
- [Yang et al. 2016]表示在情感分类问题中,”good”和”bad”这两个单词的重要性是与文本内容相关的。
- [Chan et al. 2016]注意到在语音识别中,字符输出和音频信号之间的注意力可以正确识别音频信号中第一个字符的起始位置,并且对于具有声学相似性的单词,注意力权重是相似的。
- [Kiela et al. 2018]发现multi-representational attention对 GloVe, FastText这两种词嵌入方式赋予了更高的权重。
另一种有趣的应用: [Lee et al. 2017] and [Liu et al. 2018]提供了一种注意力可视化的工具
尽管许多人用注意力来提高AI模型的可解释性,但有些人也提出了相反的观点。 [Jain and Wallace 2019]提出注意力权重与特征重要性分析是不相关的。他们观察预测结果对注意力权重改变的敏感度,却发现通过使用随机排列和adversarial training并没有改变输出结果。[Serrano and Smith 2019] applied a different analysis based on intermediate representation erasure method and showed that attention weights are at best noisy predictors of relative importance of the specific regions of input sequence, and should not be treated as justifications for model’s decisions. (又没看懂………….)
未来的研究方向
- Real-time Attention
类似实时翻译的应用需要在获得整个输入之前开始预测结果,这就需要Real-time Attention。
相关的成果:- [Chiu and Raffel 2017]
- [Ma et al. 2019]
Stand-alone Attention
相关成果:- [Ramachandran et al. 2019]
- [Wang et al. 2020e]
Model Distillation
相关成果:- [Wang et al. 2020d]
- [Mirzadeh et al. 2020]
- [Touvron et al. 2020]
Attention for Interpretability
相关成果- [Mohankumar et al. 2020]
Auto-learning Attention
相关成果:- [Ma et al. 2020]
Multi-instance Attention
相关成果:- [Li et al. 2019a]
Multi-agent Systems
相关成果:- [Fujii et al. 2020; Li et al. 2020a]
Scalability
相关成果:- [Sukhbaatar et al. 2019b]
- [Choromanski et al. 2021]
- [Wang et al. 2020a]
- [Li et al. 2020b]

