Evaluating Differentially Private Machine Learning in Practice
Bargav Jayaraman and David Evans, University of Virginia
摘要:差分隐私可以用来计算一个机制泄露了多少隐私(用$\epsilon$表示)。当用于机器学习时,差分隐私的目标即为限制模型泄露的训练集中单个个体的隐私量。但是目前人们对于如何校准$\epsilon$还不是很了解。在机器学习中人们通常会设定一个很大的$\epsilon$值来获得更好的可用性,但对这种选择对隐私所造成的影响所知甚少。此外,在使用迭代学习程序的情况下,经常使用宽松的差分隐私定义,这似乎减少了所需的隐私预算,但人们对隐私性和可用性之间的平衡理解并不深刻。在这篇文章中,我们在逻辑回归和神经网络模型的实验中量化了这些选择对隐私的影响。我们的主要的发现是获取隐私是需要代价的——宽松的差分隐私定义减少了所需的噪声数量但同时增大了隐私泄露的风险。现有的差分隐私机器学习机制很少会对复杂学习任务做可接受的可用性与隐私性之间的平衡:降低准确率损失会降低隐私性,提供强隐私保障的会产生无用的模型。
主要内容:通过实验验证不同的$\epsilon$值和使用不同的宽松的差分隐私定义对模型可用性与隐私性的影响。
几种宽松的差分隐私定义
主要思想:多种差分隐私机制组合起来时其整体的privacy budget(暂且称为隐私代价)不一定为各个privacy budget之和。可以通过一些其他的规律来获得一个更紧的上界。
- advanced composition theorem :考虑到隐私损失的期望,可以获得$\epsilon$的一个更紧的上界。
- Concentrated Differential Privacy (CDP) :$\mathcal{D}_{subG}(\mathcal{M}(D)||\mathcal(D’))\le(\mu,\tau)$。任何$\epsilon-DP$算法都满足$(\epsilon \cdot(e^{\epsilon}-1)/2,\epsilon)-CDP$ ,反过来不一定满足。
- Zero-Concentrated Differential Privacy (zCDP) :$\mathcal{D}_{\alpha}(\mathcal{M}(D)||\mathcal(D’))\le \xi + \rho a$。如果$\mathcal{M}$满足$\epsilon-DP$,则它满足$(\frac{1}{2}\epsilon^2)-zCDP$。如果它满足$\rho-zCDP$,则对任意$\delta>0$它满足$(\rho+2\sqrt{\rho log(1/\delta),\delta})-DP$
- Rényi Differential Privacy (RDP) :$\mathcal{D}_{\alpha}(\mathcal{M}(D)||\mathcal{M}(D’))\le \epsilon$。如果$\mathcal{M}$满足$(\alpha,\epsilon)-RDP$,则对于任意$0<\delta<1,$满足$(\epsilon+\frac{log(1/\delta)}{\alpha-1},\delta)-DP$

实验方法
实验设定
- 使用逻辑回归模型(凸优化)和神经网络模型(非凸)作为目标模型。
- 使用成员推断和属性推断作为攻击方式,从而获得模型的隐私损失。
- 在梯度上添加扰动。
- 使用具有两个隐藏层的神经网络作为推断(攻击)网络
攻击方式
成员推断使用Shokri(1)和Yeom(2)的方法。
- 黑盒攻击。攻击者可以获得目标模型对输入的置信度(confidence score)。使用相同分布下采样的数据训练了多个影子模型。使用这些影子模型训练推断模型。推断模型的训练集来源于部分用来训练影子模型的训练数据和一些相同分布下随机采样的数据。推断模型的输入还包括影子模型对这些数据的置信度。
- 白盒攻击。假设攻击者可以访问训练集在目标模型上的平均损失。如果输入数据在目标模型上的损失值小于均值的话就认为这个输入在目标模型的训练集里。
属性推断:使用Yeom的方法。与上2类似。暴力搜索隐私属性的所有可能值,选择与平均损失最接近的组合。
数据集
选择两个数据集
- CIFAR-100 (28×28 images)。使用PCA把维度压缩到50
- Purchase-100
每个数据集中分别随机选10,000 个作为训练集,10000个作为测试集。剩下的用来训练影子模型和推断模型。
在进行属性推断攻击时,因为原数据集没有标注哪些属性为隐私属性,所以随机选取5个属性作为隐私属性。
评价指标
- accuracy loss:没有隐私保护的模型在测试集上的准确率(baseline) - 有隐私保护的模型的准确率
- privacy leakage:真阳率(True Positive Rate) - 假阳率(False Positive Rate)。如果是0的话代表没有隐私泄露。
超参数
训练模型时使用$l_2$正则化。首先使用grid search训练一个非隐私模型,从而找到一个最大化测试集正确率的$\lambda$。
对于CIFAR-100
- 逻辑回归:$\lambda = 10^{-5}$
- 神经网络:$\lambda = 10^{-4}$
对于Purchase-100
- 逻辑回归:$\lambda = 10^{-5}$
- 神经网络:$\lambda = 10^{-8}$
然后用上面的设定训练隐私模型。$\epsilon$取值范围为$0.01-1000$,$\delta$固定为$10^{-5}$(假设训练集大小为n, $\delta\lt\frac{1}{n}$)
使用ADAM优化器,固定学习率为0.01.
batch size = 200
Clipping
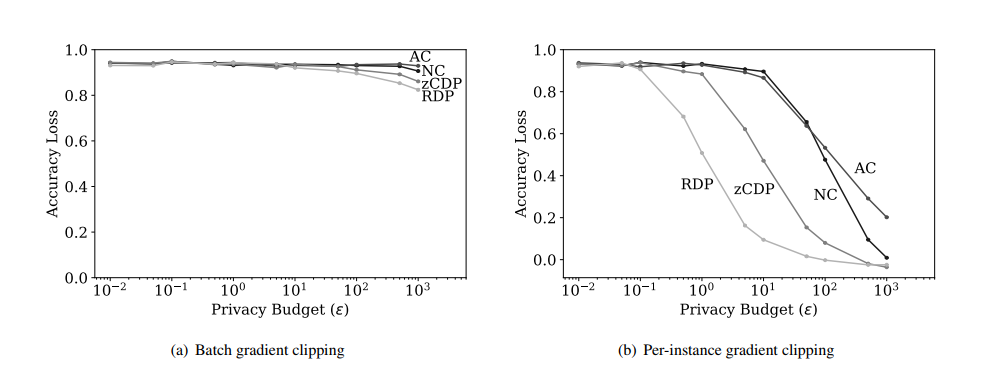
使用Tensorflow Privacy框架实现了batch clipping 和 per-instance clipping。阈值$\mathcal{C}=1$。通过下图的比较结果发现Per-instance clipping放大了不同机制之间的差异。因此后面的实验中只使用这一种clipping方式。
实验结果
逻辑回归
CIFAR-100
baseline在训练集上的准确率是0.225,测试集上的准确率是0.155。中间的gap值为0.07。上图(b)显示了不同$\epsilon$值,不同差分隐私定义对准确率损失的影响。
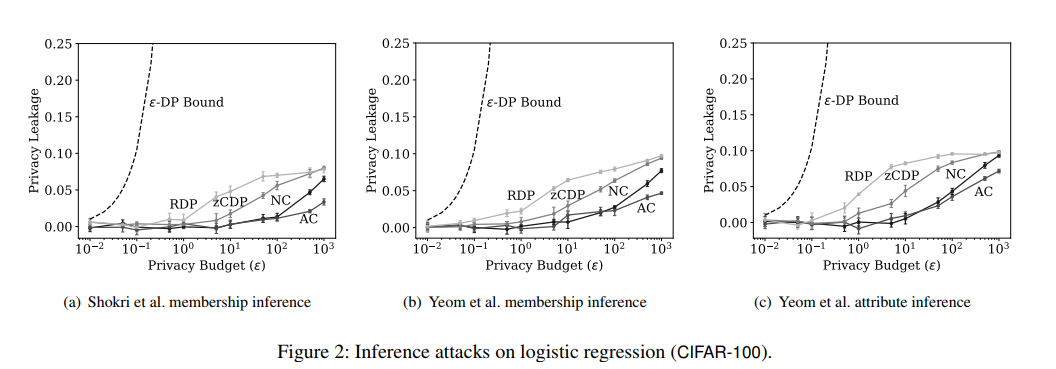
下图(a) (b)展示成员推断攻击下的隐私损失,(c)展示了属性推断攻击下的隐私损失。
通过(a)看出对于Naive composition来说,当$\epsilon\le10$时隐私损失基本为0,当$\epsilon=1000$隐私泄露达到了$0.065\pm0.004$,同时RDP和zCDP的损失之达到了$0.08\pm0.004$。通过图(b)可以看出naive-composition在$\epsilon\le 10$时没有明显的隐私损失。但是当$\epsilon=1000$时损失快速上升到$0.093\pm0.002 $。
图中还显示了$\epsilon-differential\quad privacy$的理论损失上界:$e^{\epsilon}-1$ [Yeom et al]。
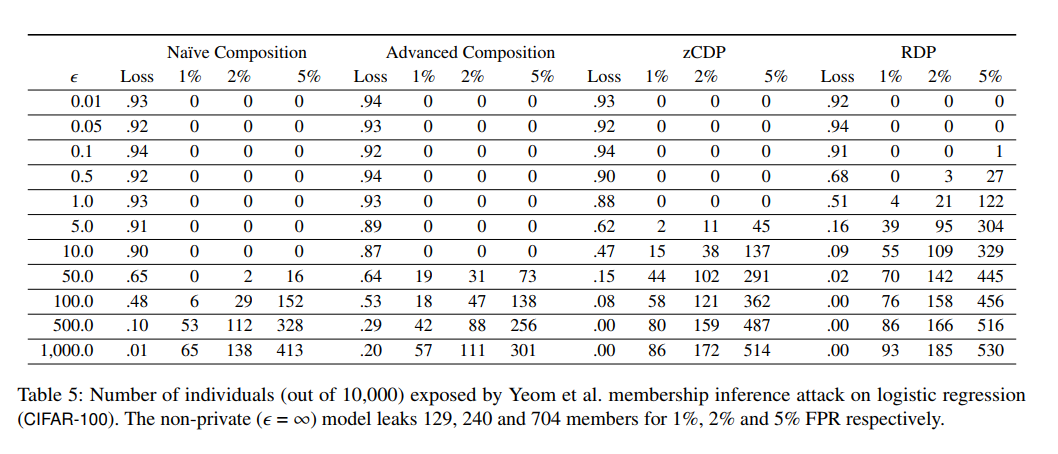
下面的图表展示了不同的差分隐私定义下泄露给敌手的训练集成员数量。
实验结论后面还有好多,与上面的大同小异,不一一展示了。
结论
获取隐私是有代价的(that there is no way to obtain privacy for free )
代码
https://github.com/bargavj/EvaluatingDPML
参考
收获
实验方法
在机器学习中应用差分隐私