《Feature Importance Estimation with Self-Attention Networks》 研读报告
摘要:黑盒神经网络模型被广泛应用于工业界和科学研究,但目前还很难以去理解和翻译。最近,注意力机制的提出为神经语言模型的内部工作原理提供了insight。本文探讨了使用基于注意力的神经网络机制来估计特征重要性,作为解释从命题(表格)数据中学习的模型的手段。由提议的自注意力网络 (SAN) 架构评估的特征重要性估计值与已建立的基于 ReliefF、互信息和随机森林的估计值进行比较,这些估计值在实践中广泛用于模型解释。我们首次在 10 个真实和合成数据集上跨算法对特征重要性估计进行无标度比较,以研究所得特征重要性估计的异同,表明 SAN 识别出与其他方法相似的高等级特征。我们证明 SAN 识别特征交互,在某些情况下,这些交互产生比基线更好的预测性能,这表明注意力超出了几个关键特征的交互,并检测到与所考虑的学习任务相关的更大的特征子集。
Introduction
这篇文章提出了自注意力网络(Self-Attention Networks ,即SANS)的概念,并且探索了这种网络学习到的“表示”是否可以用于重要性估计。主要贡献如下:
- 提出SAN,这是一种可以直接获得特征重要程度的神经网络。
- 对比ReliefF, Mutual Information 和Genie3等feature rank算法进行可拓展的经验评估。
- 针对特征重要度估计机型直接比较,突出考虑的算法输出之间的相似性
- 对SAN的属性进行理论研究,包括空间复杂度和时间复杂度。
Self-Attention Networks
本文实现了注意力机制的神经网络可以表示为:
图示如下:
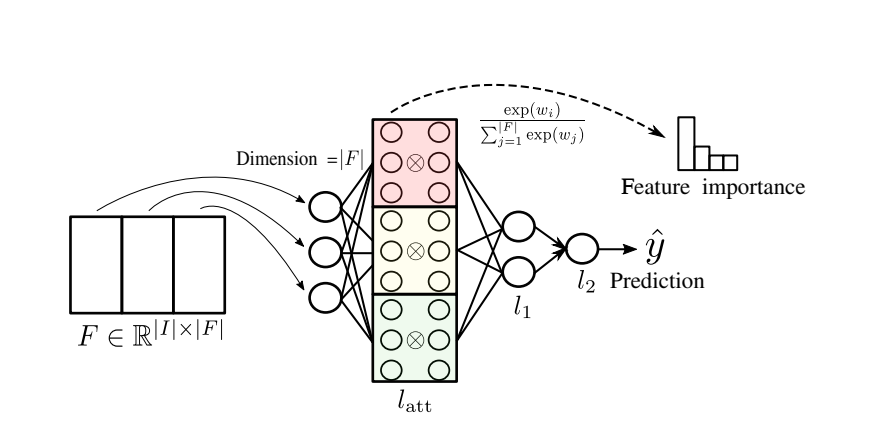
其中:
k表示注意力头的个数。$\oplus$表示Hadamard summation,$\otimes$表示Hadamard product。如下:
这篇论文中使用的多头注意力与Transformer的多头注意力机制是不一样的。Transformer使用的多头注意力机制是将Q、K、V映射到更低的维度计算注意力,重复h次后将得到的所有注意力向量拼接到一起。而该论文使用的多头注意力是将所有的注意力向量相加做平均。
Computing feature importance with SANs
下面展示如何利用上述结构获得特征的重要性权重。
- Instance-level aggregations (attention):令$\{(x_i,y_i),1\le i \le n\}$为样本集合,令$SAN(x_i)$表示第i个样本对应的注意力权重。
获得注意力的第一个选择就是将每个样本的注意力做均值:
- Counting only correctly predicted instances (attentionPositive):第二种变体基于如下的假设:只考虑被正确预测的样本。
- Global attention layer (attentionGlobal): 前面的两种方式通过累加注意力向量来获得全局的特征重要性。但是基于权重向量包含特征重要性信息的假设,可以在训练结束后直接获得全局的注意力权重。

