CADE: Detecting and Explaining Concept Drift Samples for Security Applications
Abstract
Concept drift poses a critical challenge to deploy machine learning models to solve practical security problems. Due to the dynamic behavior changes of attackers (and/or the benign counterparts), the testing data distribution is often shifting from the original training data over time, causing major failures to the deployed model.
To combat concept drift, we present a novel system CADE aiming to 1) detect drifting samples that deviate from existing classes, and 2) provide explanations to reason the detected drift. Unlike traditional approaches (that require a large number of new labels to determine concept drift statistically), we aim to identify individual drifting samples as they arrive. Recognizing the challenges introduced by the high-dimensional outlier space, we propose to map the data samples into a low-dimensional space and automatically learn a distance function to measure the dissimilarity between samples. Using contrastive learning, we can take full advantage of existing labels in the training dataset to learn how to compare and contrast pairs of samples. To reason the meaning of the detected drift, we develop a distance-based explanation method. We show that explaining “distance” is much more effective than traditional methods that focus on explaining a “decision boundary” in this problem context. We evaluate CADE with two case studies: Android malware classification and network intrusion detection. We further work with a security company to test CADE on its malware database. Our results show that CADE can effectively detect drifting samples and provide semantically meaningful explanations.
概念漂移对于部署机器学习模型以解决实际安全问题构成了重大挑战。由于攻击者(和/或良性对手)的动态行为变化,测试数据分布通常会随时间从原始训练数据中漂移,导致已部署模型的重大故障。
为了应对概念漂移,我们提出了一个新颖的系统 CADE,旨在实现以下两个目标:1)检测偏离现有类别的漂移样本,以及2)提供解释来推断检测到的漂移的原因。与传统方法不同(传统方法通常需要大量新标签来统计性地确定概念漂移),我们的目标是在漂移样本到达时识别它们。考虑到高维度离群值空间引入的挑战,我们提出将数据样本映射到低维空间,并自动学习一个距离函数来度量样本之间的差异。通过对比学习,我们可以充分利用训练数据集中的现有标签,以学习如何比较和对比样本对。为了推断检测到的漂移的含义,我们开发了一种基于距离的解释方法。我们证明,在这个问题背景下,解释“距离”要比传统方法(集中于解释“决策边界”)更有效。我们通过两个案例研究对 CADE 进行了评估:Android恶意软件分类和网络入侵检测。我们还与一家安全公司合作,在其恶意软件数据库上测试了 CADE。我们的结果表明,CADE 能够有效地检测漂移样本并提供有意义的解释。
Intro
在本文中,我们提出了一种新的方法,用于检测漂移样本,并配以一种解释检测决策的新方法。总体而言,我们构建了一个名为“CADE(Contrastive Autoencoder for Drifting Detection and Explanation)”的系统。关键挑战在于推导一个有效的距离函数来衡量样本的不相似度。与随意选择距离函数不同,我们利用对比学习的思想来从现有的训练数据中(基于现有标签)学习距离函数。给定原始分类器的训练数据(多个类别),我们将训练样本映射到低维潜在空间。映射函数通过对比样本来学习,以扩大不同类别样本之间的距离,同时减小相同类别样本之间的距离。我们展示了潜在空间中产生的距离函数能够有效地检测和排名漂移样本。
为了解释漂移样本,我们确定了一小组重要的特征,这些特征区分了这个样本与其最近的类别。一个关键观察是传统的(监督)解释方法效果不佳。洞察力在于监督解释方法需要漂移样本和现有类别都有足够的样本来估计它们的分布。然而,鉴于漂移样本位于训练分布之外的稀疏空间,这个要求很难满足。相反,我们发现基于距离变化的解释更有效,即导致漂移样本与其最近类别之间距离发生最大变化的特征。
贡献:
- 我们提出 CADE 来补充现有的基于监督学习的安全应用,以应对概念漂移。我们引入了一种基于对比表示学习的有效方法,用于检测漂移样本。
- 我们阐明了监督解释方法在解释离群样本方面的局限性,并为这种情境引入了一种基于距离的解释方法。
- 我们对提出的方法进行了广泛的评估,涉及两个应用领域。我们与一家安全公司进行的初步测试表明,CADE是有效的。我们已经在此处发布了CADE的代码,以支持未来的研究。
Background and Problem Scope
概念漂移
概念漂移指的是测试集分布会随着时间变化,导致真实的决策边界发生偏移。这通常会让模型的预测性能随着时间降低。
为了检测概念漂移,研究人员提出了各种技术,主要涉及收集新的数据集以对模型行为进行统计评估。在一些研究中,这些工作还需要进行数据标注的努力。在安全应用中,首先了解新攻击的存在并收集与之相关的数据是具有挑战性的。此外,标注数据是耗时且需要相当专业知识的工作。因此,假设大部分输入数据都能被充分标注是不切实际的。
问题空间
与使用充分检测和充分标注的数据来检测概念漂移不同,我们对单个样本进行研究,从而发现那些偏离原始样本的数据。这使得我们可以在这种漂移样本到来时检测出概念漂移并标注它们。一旦我们收集到了足够多的数据,就可以直接启动模型重训练。
在多分类问题中,存在着两种概念漂移:
- 新类别的引入
- 类别内的变化
在这篇文章中,我们主要关注第一类漂移
可能的解决方案及限制
- 第一个方法是使用原始分类器的预测概率。更具体地说,一个监督分类器通常会输出一个预测概率(或置信度),作为预测标签的附带产品。例如,在深度神经网络中,通常使用softmax函数来生成预测概率,该概率表示给定样本属于每个现有类别的可能性(总和为1)。因此,低的预测概率可能表明输入样本与现有的训练数据不同。然而,我们认为在我们的问题背景下,预测概率不太可能有效。原因是该概率反映了相对于现有类别的适应度(例如,样本在类别A中的适应程度优于类别B)。如果样本来自一个全新的类别(既不属于类别A也不属于类别B),那么预测概率可能会极具误导性。许多先前的研究已经证明,来自新类别的测试样本可能会导致误导性的概率分配(例如,将一个错误的类别与高概率关联)。从根本上讲,预测概率仍然继承了分类器的“封闭世界假设”,因此不适合检测漂移样本。
- 与预测概率相比,一个更有前景的方向是直接评估样本与给定类别的适应度(按我的理解应该就是相似度)。这个想法是,我们不是评估样本在类别A中的适应程度优于类别B,而是评估该样本在类别A中与其他训练样本的适应程度。例如,可以使用自编码器基于重构误差来评估样本对给定分布的适应度。然而,作为一种无监督方法,当忽略标签时,自编码器很难学习到训练分布的准确表示(详见第4节)。在最近的一项工作中,Jordaney等人引入了一个名为Transcend的系统。它将“非一致性度量”定义为适应度评估。Transcend使用可信度p值来量化测试样本x与属于同一类别的训练样本的相似程度。p是该类别中至少与同一类别的其他样本不相似的样本比例。虽然这个度量可以确定漂移样本,但这样的系统在很大程度上依赖于对“不相似性”的良好定义。正如我们将在第4节中展示的那样,任意的不相似性度量(特别是在数据维度高的情况下)可能导致性能不佳。
Designing CADE
我们提出了一个叫做CADE的漂移样本检测和解释系统。我们首先描述了设计背后的直觉和见解,然后是每个组件的技术细节。
设计直觉
如图一所示,我们的系统由两部分组成:
- 检测模块:检测漂移样本
- 解释模块:帮助研究人员理解此次漂移意味着什么
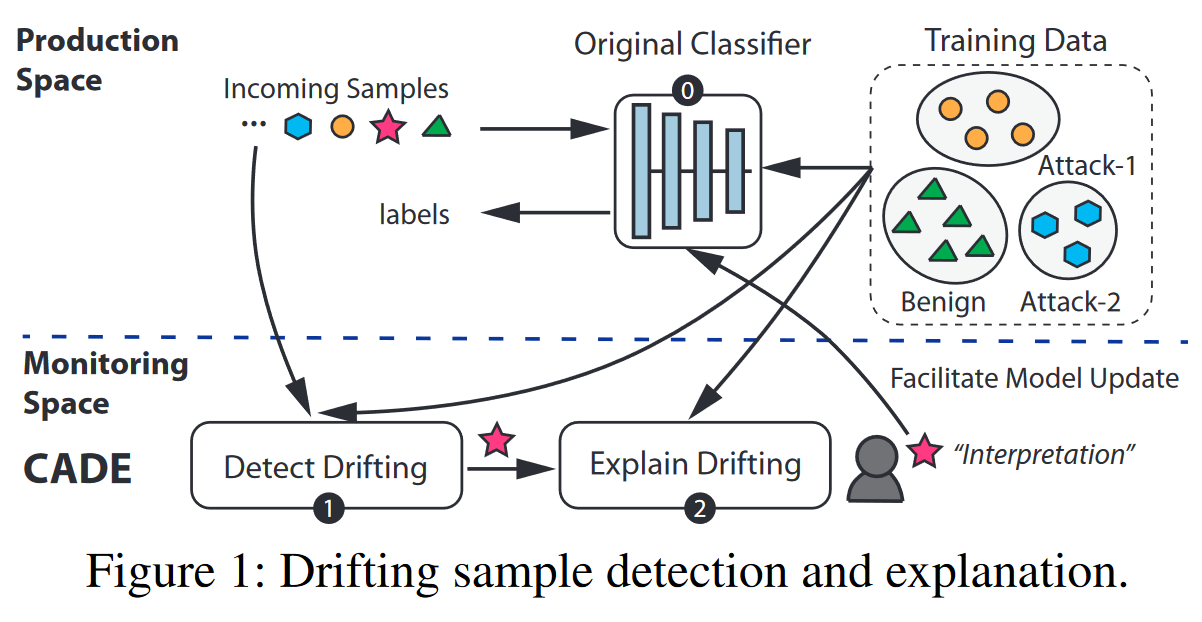
通过开始的分析,我们发现这两个任务有一个相同的挑战:漂移样本位于稀疏的离群空间,这让开发有意义的距离函数变得非常困难。
首先,检测漂移样本需要学习一个良好的距离函数,以度量“漂移样本”与现有分布的差异。然而,异常值空间具有无限大且稀疏的特点。对于高维数据,由于“维数诅咒” ,距离的概念开始失去效力。其次,解释的目标是识别一个重要特征的小子集,最有效地区分漂移样本和训练数据。因此,我们还需要一个有效的距离函数来度量这些差异。
在接下来的部分中,我们设计了一个漂移检测模块和一个解释模块,共同解决这些挑战。在高层次上,我们首先使用对比学习来学习训练数据的压缩表示。对比学习的一个关键优势是它可以利用现有标签,相对于无监督方法如自动编码器和主成分分析(PCA),实现了更好的性能。这使我们能够从训练数据中学习距离函数以检测漂移样本(第3.2节)。至于解释模块,我们将描述一种基于距离的解释公式,以解决前面提到的挑战(第3.3节)。
漂移样本检测
漂移检测模型通过检测输入样本实现离群点的检测。
对比学习实现特征隐表示
我们探讨了对比学习的思想,以学习训练数据的良好表示。对比学习利用训练数据中的现有标签来学习一个有效的距离函数,以度量不同样本之间的相似性(或对比)。与监督分类器不同,对比学习的目标不是将样本分类到已知类别,而是学习如何比较两个样本。
如图二所示,对比学习的目的是将输入映射到低维的隐空间。经过映射后,同一类的样本距离更小,不同类的样本距离更大。因此,隐空间中的距离度量可以反映出样本对的差异。任何与所有现有类别表现出较大距离的新样本都有可能是漂移样本。
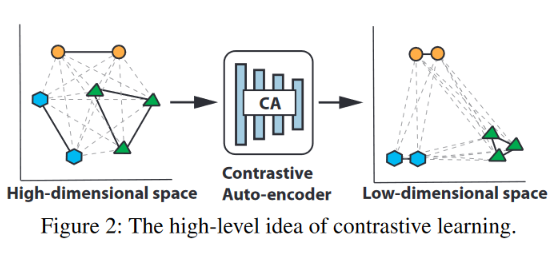
为了实现这个想法,我们使用了一个带有对比损失的自动编码器。自编码器是学习给定输入分布的压缩表示(具有降低的维度)的有用工具。形式上,让$x\in\mathbb{R}^{1\times 1}$是训练集中的一个样本。我们训练一个包含编码器$f$和解码器$h$的自动编码器。$f,h$的参数分别为$\Theta,\Phi$。损失函数如下:
该损失函数包含两项:
- 重建损失$\mathbb{E}_{\boldsymbol{x}}|\boldsymbol{x}-\hat{\boldsymbol{x}}|_2^2$。即自动编码器对原样本进行重建后得到的样本与原样本距离的二范数。在这个自动编码器中,编码器$f$将$x$映射到一个低维向量$z=f(x,\Theta)$。自动编码器保证这个向量可以以较小的重建损失重建这个样本。
- 对比损失$\lambda\mathbb{E}_{\boldsymbol{x}_i,\boldsymbol{x}_j}\left[(1-y_{ij})d_{ij}^2+y_{ij}(\boldsymbol{m}-d_{ij})_+^2\right]$。$(x_i,x_j)$是一个样本对。$y_{i,j}$表示两个样本之间的关系。如果两个样本来自不同的类别,则值为1,否则为0。$(.)_+$是$max(0,.)$的缩写。$d_{i,j}$是样本隐表示$z_i=(x_i;\Theta),z_j=f(x_j;\Theta)$之间的欧几里得距离。$z\in \mathbb{R}^{d\times 1}$。使用该损失,模型会最小化统一类别的样本距离,同时最大化不同类别之间的样本距离(这个距离最大被限制到m)。
经过对比学习后,$f$可以把相同类别的样本映射为一个较紧的样本簇。在隐空间中使用距离函数就可以把漂移样本检测出来。
基于MAD的漂移样本检测
在训练好自动编码器之后,我们就可以使用它来检测漂移样本了。给定$K$个测试样本$\{x_t^{(k)}\}(k=1,\dots,K)$,我们寻求一种方法可以找到这些样本中的漂移样本。检测方法如算法1所示。

假设训练集有$N$个类别,每个类别有$n_i$个训练样本。我们首先把所有的训练样本映射到隐空间中(2-4行)。对于每个类别$i$,我们可以计算出一个中心$c_i$(就是直接取样本均值)。对于待检测的测试样本$x_t^{(k)}$,我们同样需要把它映射到隐空间中得到$z_t^{(k)}$(第14行)。接着我们计算测试样本和每个中心之间的欧几里得距离$d_i^{(k)}$。我们基于这个距离判断测试样本是否为离群点。在这我们不使用离测试样本最近的样本点的原因是,训练集中的离群点会影响判断。
不同的类别有不同的紧凑程度,故对于不同的类别需要使用不同的阈值。我们没有为每个类别手动设定阈值,而是使用了一种叫做“绝对中位差(Median Absolute Deviation,MAD)“的方法。计算出某一类的中心后,需要计算该类每个样本与中心的距离。距离中位数记为$\tilde{d}_i$。则:
基于$MAD_i$,我们就可以决定$d_i^{(k)}$是不是所有类别的离群点。MAD的优势是每个类别都有一个独立的距离阈值,而且这个阈值和每一类的分布相关。举例来说,如果一个类别更分散,则这个阈值会更大。
需要注意的是,当一个类没有足够的样本时,MAD可能会受到影响,因为它的中值可能容易受噪声影响。在我们的设计中,对比学习可以帮助缓解这个问题,因为每个类被映射到潜在空间中的一个紧凑区域,这有助于稳定中位数。
排序
正如图一所示,研究人员或许需要对漂移样本进行进一步的研究来解释漂移的含义。在研究时间有限的情况下,对每个漂移样本进行排序是非常有必要的。我们使用了一个非常朴素的方法进行排序,即每个样本与最近类别中心的距离(这个距离由27行计算得到)。这让我们可以优先研究距离中心最远的样本。
排序是否也要考虑不同类别之间的离散程度呢?按照我的理解,本文应该是在各个中心的周围选最远的漂移样本。也就是说n个类别就会有n个最远的漂移样本。
解释漂移样本
前面论文中说本文关注的是两种概念漂移中的第一种,即本文中的概念漂移指的是出现了新的类别,而不是类内分布发生变化。但这里却尝试解释漂移样本为啥从某一个类别中漂出来了。按理说新类别中的样本应该和其它类别没啥关系。
解释模型的目的是找到致使样本产生漂移的最重要的特征(重要指的是对漂移现象重要)。给定一个漂移样本$x_t$和离它最近的类别$y_t$,我们需要找出来一个使得$x_t$成为$y_t$离群点的特征的子集。为了实现这个目标,直觉上我们可以把问题转化为监督学习模型的可解释性。举个例子,我们可以把漂移检测器当作是一个分类器(二分类,漂移或者没漂),然后利用现有的对于分类器的解释手段来解释漂移现象。然而,由于利群空间的高度稀疏性,我们发现想让一个漂移样本跨国决策边界是很难的,从而导致解释失败。受此启发,我们针对漂移检测设计了一种新的解释方法。这种解释方法解释了漂移样本和类内样本之间的距离,而不是决策边界。下面,我们首先分析直觉上的想法,然后再解释我们的方法。
直觉上的方法:略
我们的方法:基于距离的解释
与有监督分类器不同,漂移检测器的决策基于样本与类别中心的距离。于是我们的目标就是从原始特征中找到使概念漂移发生的(特征)子集。在这种设定下,我们不需要让$x_t$跨越决策边界。我们只需要在原始样本上添加扰动,并观察隐空间中样本的变化。
在这种设定下,选取出来的特征似乎和编码器的映射方式有很大的关系。
为了实现这种想法,我们需要设计一种扰动机制。大多数现存的机制都是为图像数据设计的。而我们需要一种既可以作用于连续数据,也可以作用于离散数据的扰动机制。为了满足这种要求,我们通过把$x_t$的特征修改为$x_{yt}^{(c)}$的对应特征从而实现扰动。$x_{yt}^{(c)}$为距离类别c最近的样本点。因此,我们的目的就是寻找哪些样本修改之后会对隐空间对应的样本点造成最大的影响。将特征修改为$x_{yt}^{(c)}$的特征也保证了样本点会大致向着类别中心靠近。
我们用$m\in \mathbb{R}^{q\times 1}$表示重要特征。$m$是一个掩码,值为1表示此处的特征被替换。 每一个$m_i$都可以以概率$p_i$从伯努利分布中采样。下面我们的问题就转化为了求解$p_{1:q}$使下面的式子最小:
$\tilde{z}_t$是扰动样本的隐空间向量。$R(m,b)$控制了$m$中非0元素的个数。为了加快速度,用$b$表示一个pre-filter,如果$(x_t)_i=(x_{yt}^{(c)})_i$ ,则$(b)_i=0$。也就是不对 漂移样本和中心附近的样本相同的分量 做优化。
注意到伯努利分布是离散的,我们不能直接用梯度下降的方式解决这个问题,所以我们使用了伯努利分布的连续近似分布来进行求解。
评估:漂移检测
我们使用两个数据集进行评估
- Drebin:Android 恶意软件检测数据集。我们从中选取了8类样本,每一类样本至少有100条记录(总共3317个样本)。在实验之前,随机选取一类作为漂移样本,漂移样本只存在于测试集中。我们的目标是在测试阶段正确的识别出漂移样本。训练集和测试集按照时间顺序8-2分。通过特征筛选,最后得到了1340条特征。为了使实验结果更具有普适性,我们迭代的选择每一个类别作为漂移类并重复实验。
- 网络入侵检测系统:CICIDS-2018。为了加速实验,我们选择了10%的流量作为实验数据集。其它数据集分割及实验方式和上述一致。
使用精准率、召回率、F1-score等作为评价指标。使用两种方法作为baseline:
- Vanilla autoencoder。用它来进行数据降维,使用本文的方法做漂移检测。用来说明对比学习的优势。
- Transcend。Transcend定义了一个”非一致性测度”来量化传入样本与预测类别的吻合程度,并计算可信度p值来判断传入样本是否为漂移样本。
评估结果
漂移样本检测性能。我们首先使用一个实验设置来解释我们的评估过程。以Drebin数据集为例。假设我们将Iconosys家族作为测试集中以前未见的家族。在训练检测模型(不包含任何Iconosys样本)之后,我们使用该模型来检测和排名漂移样本。为了评估排名列表的质量,我们模拟了一位分析师从列表顶部检查样本的过程。
图4a显示,当我们检查更多的漂移样本(最多150个样本)时,精确度保持在较高水平(超过0.97),而召回率逐渐达到100%。结合精确度和召回率,最高的F1得分为0.98。在150个样本之后,精确度将下降,因为剩余集合中没有更多未见类别的样本了。这证实了排名列表的高质量,意味着几乎所有来自未见家族的样本都排在了最前面。
与之相比,Transcend和Vanilla AE的排名列表并不令人满意。对于Transcend(图4b),前150个样本的精确度和召回率都很低,表明排名靠前的样本并不来自未见家族。在检查了150个样本之后,我们开始看到更多来自未见家族的样本。在检查了350个样本之后,Transcend已经涵盖了大部分来自未见家族的样本(即召回率接近1.0),但精确度仅为0.46。这意味着分析师检查的样本中超过一半与问题无关。最佳的F1得分为0.63。如图4c所示,Vanilla AE的性能更差。即使在检查了600个样本之后,召回率仅略高于0.8。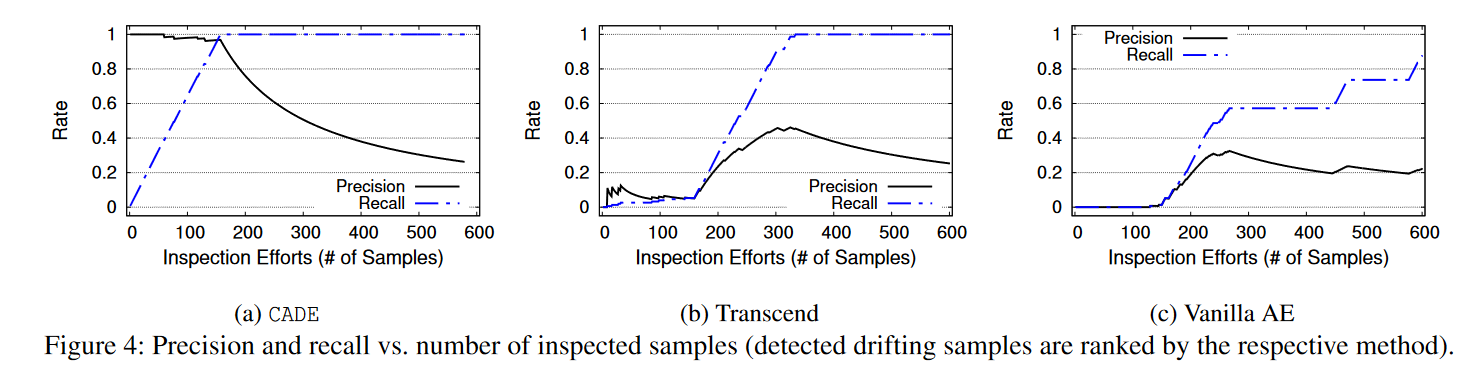
表3证实了CADE能够准确检测漂移样本,并且优于两个基准模型。在Drebin数据集上,CADE的平均F1得分为0.96,而基准模型的F1得分分别为0.80和0.72。对于IDS2018数据集,可以得出类似的结论。此外,CADE的标准差要小得多,表明在不同的实验设置中具有更一致的性能。最后,我们展示了CADE具有较低的归一化检查工作量,这证实了排名的高质量。
请注意,Transcend基准模型在某些情况下确实表现良好。例如,在IDS2018数据集中将DoS-Hulk设置为未见家族时,其F1得分为99.69%(与我们的系统类似)。然而,问题在于Transcend在不同的设置中表现不稳定,这在表3中的高标准差中得到了体现。
对对比学习的影响。为了了解性能提升的来源,我们研究了对比学习的影响。首先,我们在图7中呈现了Drebin数据集的训练样本和来自选择的未见家族(FakeDoc)的测试样本的t-SNE图。t-SNE 是一种非线性降维技术,可以将数据样本投影到二维图中进行可视化。为了可视化我们的数据样本,我们将样本从原始空间(1,340维)映射到二维空间(图7a)。同时,我们还将样本从潜空间(7维)映射到二维空间进行比较(图7b和图7c)。我们可以观察到,CADE的潜空间中的样本形成了更紧密的聚类,这使得更容易将现有样本与未见家族区分开来。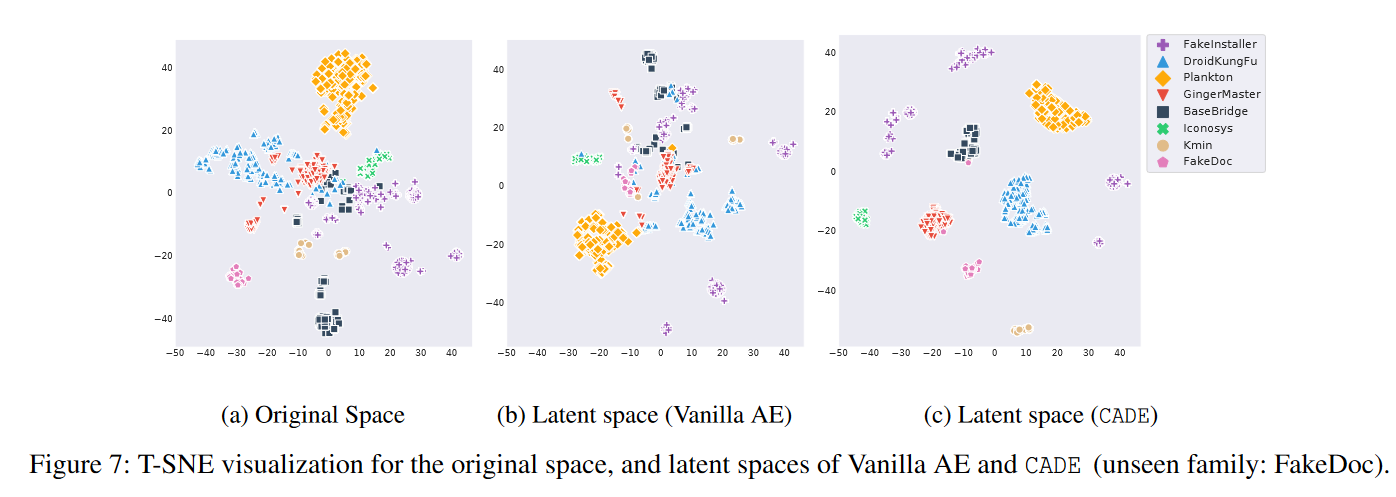
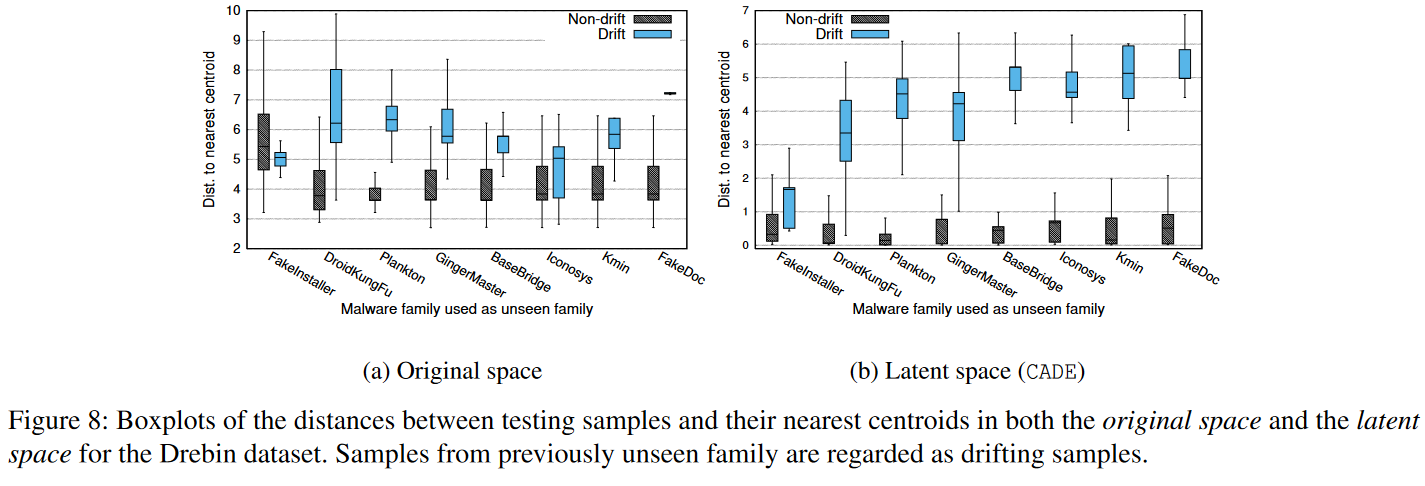
为了从统计的角度观察不同的实验设置,我们绘制了图8。与之前类似,我们迭代地将一个家族作为Drebin数据集中的未见家族。然后,我们测量测试样本到其在原始特征空间中最近质心的距离(图8a),以及CADE生成的潜空间中的距离(图8b)。IDS2018数据集的结果得出了相同的结论,为了简洁起见,省略了在此展示。我们展示了漂移样本和非漂移样本在原始空间中更难分离。经过对比学习后,潜空间中的分离更加明显。原因在于对比学习学习到了一个适合的距离函数,可以将不同类别的样本拉得更远,从而更容易检测到未见家族。
案例研究:CADE的局限性。在大多数设置中,CADE的表现良好。然而,我们发现在某些情况下,CADE的性能受到影响。例如,当将FakeInstaller作为未见家族时,我们的检测精确度仅为82%,而召回率达到100%。我们注意到,许多来自GingerMaster和Plankton家族的测试样本被检测为漂移样本。经过仔细检查,我们发现,当将FakeInstaller作为未见家族时,为了保持整体的80:20的训练-测试比例,在GingerMaster和Plankton家族尚没有足够的训练样本时,我们需要在这个时间点拆分数据集。因此,许多来自GingerMaster和Plankton家族的测试样本与这两个家族中少量训练样本(基于潜空间距离)非常不同。外部证据也表明,这两个家族有许多变种[5, 70]。虽然这些恶意软件变种不属于新的家族(根据我们的定义是误报),但它们对于研究理解同一家族内的恶意软件变异也具有价值。
评估:解释漂移样本
为了评估解释模块,在每个数据集中随机选择一个类(例如,在Drebin数据集中选择FakeDoc,在IDS2018数据集中选择Infiltration)作为漂移样本。其他设置的结果得出相同的结论,为了简洁起见,省略了这些结果。在这个设置下,我们为检测到的漂移样本生成解释,并对解释结果进行定量和定性评估。
使用三种方法作为baseline:
- random。随机选择特征作为重要特征
- 基于边界。如前文所说
- 无监督的解释方法COIN。COIN构建了一组本地的LinearSVM分类器,用于将一个个体离群值与其在分布邻域样本中进行分离。由于LinearSVM分类器是自解释的,它们可以指出对离群值分类起重要作用的特征。为了进行公平比较,我们选择了与我们的方法相同数量的顶部特征作为基线方法。这些基线方法的实现和超参数可以在附录B中找到。请注意,我们没有选择现有的黑盒解释方法(例如,LIME 和SHAP)作为我们的比较基线。这是因为白盒方法通常比黑盒方法表现更好,这要归功于它们对原始模型的访问权限。
评估指标:定量的情况下,我们直接评估选择特征带来的距离变化。给定一个测试样本$x_t$和解释方法,我们可以得到一个特征子集$m_t$。我们通过这个指标来量化这个解释结果的精确性:$d_{xt}’=||f(x_t\odot(1-m_t)+x_{yt}^{(c)}\odot m_t)-c_{yt}||_2$。这个值表示了隐空间中扰动样本和它最近的样本中心之间的距离。如果这个特征真的是重要的,那么扰动样本和最近的样本之间的距离会变小。
除了这个$d_{xt}’$指标之外,我们还使用传统的度量指标(第5.2节)来检查能够穿越决策边界的扰动样本的比例。
精确性评价结果
特征对距离的影响。表4显示了所有漂移样本的$d_{xt}’$的均值和标准差(即扰动样本到最近质心之间的距离)。我们有四个关键观察结果。首先,基于随机选择的特征扰动漂移样本几乎不会影响潜空间距离(比较行2和行3)。其次,基于边界的解释方法可以在两个数据集上降低26%–47%的距离(比较行2和行4)。这表明这种策略具有一定的有效性。然而,绝对距离值仍然很高。第三,COIN减小了IDS2018数据集中的潜空间距离(比较行2和行5),但在Drebin数据集中平均距离却有所增加。实质上,COIN是一种专门的基于边界的方法,它使用一组LinearSVM分类器来逼近决策边界。我们发现COIN在高维空间上效果不好,并且很难将漂移样本拉过边界(将在第5.3节讨论)。最后,我们在CADE中的解释模块具有最低的距离度量均值和标准差。距离与原始距离相比显著降低(即在Drebin上降低了98.8%,在IDS2018上降低了79.9%,比较行2和行6)。特别是,CADE在边界解释方法方面表现出色。由于我们的方法克服了样本稀疏性和不平衡的问题,它能够准确指出对距离(影响漂移检测决策)有更大影响的有效特征。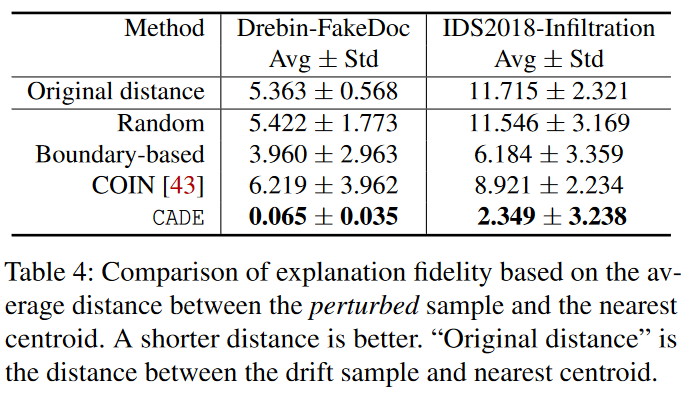
选择的特征数量。总体而言,选择的特征数量较少,这使得手动解释成为可能。如前所述,我们将所有方法配置为选择相同数量的重要特征(与CADE相同)。对于Drebin数据集,平均选择的特征数量为44.7,标准差为6.2。这在1000多个特征中只占很小一部分(3%)。类似地,IDS2018数据集的平均选择特征数量为16.2,约占所有特征的20%。
跨越决策边界
上述评估结果证实了所选特征对距离度量的影响,而这恰恰是CADE旨在优化的内容。为了提供另一个视角,我们进一步研究了所选特征对穿越决策边界的影响。具体而言,我们计算了成功穿越决策边界的扰动样本的比例。如表6所示,我们确认在漂移检测的上下文中,大多数情况下穿越边界是困难的。特别是,CADE能够将97.64%的扰动样本推动穿越Drebin数据集的检测边界,但只有1.41%的样本能够穿越IDS2018数据集的边界。相比之下,基线方法在原始特征空间中很少能够成功扰动漂移样本使其穿越边界。通过放宽这个条件并专注于距离变化,我们的方法在确定重要特征方面更加有效。
样例学习
为了证明我们的方法确实捕捉到了有意义的特征,我们展示了一些案例研究。在表5中,我们展示了Drebin数据集的一个案例研究。我们选择了FakeDoc是未见过的家族,并随机选择一个漂移样本来运行解释模块。在1000多个特征中,我们的解释模块确定了42个重要特征,其中27个特征的值为“1”(表示该样本包含这些特征)。如表5所示,最接近的家族是GingerMaster。
我们手动检查这些特征,以确定它们是否具有正确的语义含义。虽然很难获取“地面真相”的解释,但我们收集了有关FakeDoc恶意软件和GingerMaster的外部分析报告[68, 70]。根据这些报告,与GingerMaster相比,FakeDoc恶意软件的一个关键区别是它通常通过短信订阅高级服务并向受害用户收费。如表5所示,许多选定的特征与读取、写入和发送短信的权限和API调用有关。我们突出显示了与短信相关功能匹配的这些特征。其他相关特征也被突出显示。例如,“RESTART_PACKAGES”权限允许恶意软件终止后台进程(例如显示传入短信的进程),以避免提醒用户。权限“DISABLE_KEYGUARD”允许恶意软件在不解锁屏幕的情况下发送高级短信消息。“WRITE_SETTINGS”有助于偷偷写入系统设置以发送短信。”https://ws.tapjoyads.com/“ 是FakeDoc通常使用的广告库。再次强调,这小部分特征是从1000多个特征中选择出来的。我们得出结论,这些特征高度指示了该样本与最近的已知家族有何不同
评估:类内漂移
到目前为止,我们的评估主要集中在一种概念漂移类型(类型A),即漂移样本来自以前未见过的家族。接下来,我们探索如何调整我们的解决方案以应对另一种概念漂移类型(类型B),即漂移样本来自现有类别。我们在一个二元分类设置下进行了一项简要的实验。
更具体地说,我们首先使用Drebin数据集训练了一个二元SVM分类器,用于将恶意样本与良性样本进行分类。该分类器在Drebin数据集上表现出很高的准确性,训练时的F1得分为0.99。我们想测试该分类器在另一个名为Marvin 的Android恶意软件数据集上的表现。相对于Drebin数据集(2010年至2012年),Marvin数据集略微更新(2010年至2014年)。我们首先移除Marvin数据集中与Drebin重叠的样本,以确保Marvin样本是真正的先前未见过的。这样,Marvin数据集中剩下了9,592个良性样本和9,179个恶意样本。
在这个实验中,我们将Marvin数据集随机分成验证集和测试集(50:50)。对于这两个集合,我们保持恶意样本和良性样本的平衡比例。我们将原始的分类器(在Drebin数据上训练)应用于Marvin的测试集。我们发现由于可能存在恶意类别和/或良性类别内的评估问题,测试准确率不再很高(F1得分为0.70)。
为了解决类内漂移的问题,我们在Marvin的验证集上应用CADE和Transcend来识别少量的漂移样本(它们可以是良性或恶意的)。我们通过使用它们的“真实标签”来模拟对这些样本进行标记,然后将这些带有标签的漂移样本添加回Drebin的训练数据中,重新训练二元分类器。最后,我们在Marvin的测试集上测试重新训练的分类器。
根据表7的数据,我们发现CADE仍然明显优于Transcend。例如,通过添加仅150个漂移样本(占Marvin验证集的1.7%)进行重新训练,CADE将二元分类器的F1得分提升至0.92。而对于Transcend来说,相同数量的样本只能将F1得分提升至0.74。此外,我们还发现CADE的速度更快:CADE的运行时间为1.2小时(而Transcend需要10小时)。这个实验证实了CADE可以适应处理二元恶意软件分类器的类内演化问题。