Reinforcement Learning-Based Black-Box Model Inversion Attacks
Metadata
- Type: ConferencePaper
- Title: Reinforcement Learning-Based Black-Box Model Inversion Attacks,
- Author: Han, Gyojin; Choi, Jaehyun; Lee, Haeil; Kim, Junmo,
- Year: 2023 ;
- Pages: 20504-20513
- Publisher: IEEE,
- Location: Vancouver, BC, Canada,
- DOI: 10.1109/CVPR52729.2023.01964
Abstract
Model inversion attacks are a type of privacy attack that reconstructs private data used to train a machine learning model, solely by accessing the model. Recently, white-box model inversion attacks leveraging Generative Adversarial Networks (GANs) to distill knowledge from public datasets have been receiving great attention because of their excellent attack performance. On the other hand, current blackbox model inversion attacks that utilize GANs suffer from issues such as being unable to guarantee the completion of the attack process within a predetermined number of query accesses or achieve the same level of performance as whitebox attacks. To overcome these limitations, we propose a reinforcement learning-based black-box model inversion attack. We formulate the latent space search as a Markov Decision Process (MDP) problem and solve it with reinforcement learning. Our method utilizes the confidence scores of the generated images to provide rewards to an agent. Finally, the private data can be reconstructed using the latent vectors found by the agent trained in the MDP. The experiment results on various datasets and models demonstrate that our attack successfully recovers the private information of the target model by achieving state-of-the-art attack performance. We emphasize the importance of studies on privacy-preserving machine learning by proposing a more advanced black-box model inversion attack.
模型逆向攻击是一种隐私攻击,通过仅访问模型,重新构建用于训练机器学习模型的私有数据。最近,利用生成对抗网络(GANs)从公共数据集中提取知识的白盒模型逆向攻击引起了广泛关注,因为其具有卓越的攻击性能。另一方面,当前利用GAN的黑盒模型逆向攻击存在一些问题,比如无法保证在预定数量的查询访问内完成攻击过程,或无法达到与白盒攻击相同水平的性能。为了克服这些限制,我们提出了一种基于强化学习的黑盒模型逆向攻击。我们将潜在空间搜索问题制定为马尔可夫决策过程(MDP)问题,并通过强化学习来解决它。我们的方法利用生成图像的置信度分数来为代理提供奖励。最终,通过在MDP中训练的代理找到的潜在向量,可以重构私有数据。在各种数据集和模型上的实验证明,我们的攻击成功地恢复了目标模型的私有信息,实现了最先进的攻击性能。我们强调通过提出更先进的黑盒模型逆向攻击,进行隐私保护机器学习研究的重要性。
Introduction
随着人工智能的迅速发展,深度学习应用正在各个领域不断涌现,如计算机视觉、医疗保健、自动驾驶和自然语言处理。随着需要使用私有数据来训练深度学习模型的案例数量增加,对包括敏感个人信息在内的私有数据泄漏的关注正在上升。特别是关于隐私攻击的研究[21]表明,恶意用户可以从训练过的模型中提取个人信息。其中一种对机器学习模型最具代表性的隐私攻击是模型逆向攻击,它通过仅访问模型就能重构目标模型的训练数据。
模型逆向攻击分为三类,即1)白盒攻击,2)黑盒攻击和3)仅标签攻击,这取决于目标模型的信息量。白盒攻击可以访问模型的所有参数。黑盒攻击可以访问由置信度分数组成的软推理结果,而仅标签攻击只能以硬标签形式访问推理结果。随着对深度学习模型隐私攻击的关注增加,加强在开发和部署深度学习模型时的隐私保护机制显得尤为重要。研究人员和实践者正在积极探索提高机器学习模型隐私性的方法,包括差分隐私、联邦学习和安全多方计算等技术。随着领域的不断发展,解决隐私挑战将对确保人工智能技术的负责和道德使用至关重要。
白盒模型逆向攻击[5, 25, 27]通过使用生成对抗网络(GANs)[10]成功地恢复了包括个人信息在内的高质量私有数据。首先,它们在独立的公共数据上训练GANs以学习私有数据的一般先验。然后,由于可以访问已训练白盒模型的参数,它们利用基于梯度的优化方法搜索并找到代表特定标签数据的潜在向量。然而,这些方法无法应用于保护模型参数的机器学习服务,如亚马逊的Rekognition [1]。要从这些服务中重构私有数据,需要进行关于黑盒和仅标签的模型逆向攻击的研究。
与白盒攻击不同,这些攻击需要能够探索GANs的潜在空间的方法,以便利用它们,因为无法进行基于梯度的优化。最近提出的深度学习网络的模型逆向(MIRROR)[2]使用遗传算法在从黑盒目标模型获取的置信度分数中搜索潜在空间。此外,边界驱逐模型逆向攻击(BREPMI)[14]通过使用基于决策的零阶优化算法进行潜在空间搜索,在仅标签的设置下取得了成功。
尽管存在这些尝试,但每种方法都存在显著问题。BREP-MI从第一个生成被分类为目标类别的图像的潜在向量开始潜在空间搜索的过程。这并不保证在通过随机采样找到第一个潜在向量之前需要多少次查询访问,并且在最坏的情况下,可能无法为某些目标类别启动搜索过程。对于MIRROR,尽管它使用了置信度分数进行攻击,但其表现较仅标签攻击BREP-MI更差。因此,我们提出了一种新方法,即基于强化学习的黑盒模型逆向攻击(RLB-MI),作为解决上述问题的方案。我们整合强化学习,以从置信度分数中获得有关潜在空间探索的有用信息。更具体地说,我们将在GAN中潜在空间的探索形式化为马尔可夫决策过程(MDP)的问题。然后,我们基于生成图像的置信度分数为代理提供奖励,并使用回放内存中的更新步骤使代理能够逼近包括潜在空间在内的环境。基于这些信息选择的代理操作比现有方法更有效地导航潜在向量。最终,我们可以通过从潜在向量中经过GAN重构私有数据。我们在各种数据集和模型上进行了实验。攻击性能与三类各种模型逆向攻击进行了比较。结果表明,所提出的攻击能够通过优于所有其他攻击的性能成功地恢复有关私有数据的有意义信息。
Related Work
模型逆向攻击
模型逆向攻击是一种针对机器学习模型的隐私攻击,其目的是重构用于训练的数据。早期的研究主要关注白盒条件,即已训练的模型是完全可访问的。Fredrikson等人通过从低复杂性模型中提取敏感属性[8]和面部图像[7],展示了模型逆向攻击的严重性。然而,早期的白盒模型逆向攻击由于无法从复杂模型中重构高维数据而存在明显的局限性。
为解决这些限制,许多白盒模型逆向攻击利用了生成模型。Zhang等人[27]提出了一种名为生成模型逆向攻击(GMI)的攻击,使用在公共数据上训练的GAN [10]。他们通过搜索GAN的潜在空间而不是图像空间来重构图像。GAN的流形逼近能力有效地缩小了攻击模型的搜索空间。知识丰富的分布模型逆向攻击(KED-MI)[5]通过使用一个具有反演特定功能的GAN来改进GMI,其中鉴别器执行多类推断。反演专用GAN的鉴别器可以区分真实数据和伪造数据,并且可以预测目标网络的输出。这使得反演专用GAN能够从公共数据中提取目标模型的有用知识。此外,KED-MI通过提取目标类别数据的分布,而不仅仅是目标类别的一个训练数据,可以创建多样化的图像。变分模型逆向攻击(VMI)[25]将模型逆向攻击形式化为包含深度标准化流和styleGAN [15]框架的变分推断问题。
不幸的是,白盒攻击并不适用于在训练模型的参数没有信息的情况下。因此,提出了仅需要访问软标签的黑盒模型逆向攻击。基于学习的模型逆向攻击(LBMI)[26]使用类似于自动编码器的结构来训练一个反演模型,该模型以与目标网络相反的方式行为。反演模型不仅需要访问攻击者构造的查询,还需要访问用户输入数据的置信度分数,该数据是反演的目标。Salem等人[22]提出了一种攻击,通过计算模型更新前后输出的差异来泄露用于更新的训练数据的信息。这两种方法都有一个局限,即它们需要攻击者通常难以访问的信息。深度学习网络的模型逆向(MIRROR)[2]表明可以利用GANs在黑盒模型逆向攻击中使用遗传算法。此外,提出了一种仅标签的模型逆向攻击,边界排斥模型逆向攻击(BREPMI)[14]。BREP-MI在反演过程中仅使用硬标签。BREP-MI从当前潜在向量为中心的球面上的点的标签估计梯度。使用估计的梯度更新潜在向量,使得GAN从潜在向量中重构目标类别的代表性图像。
深度增强学习
使用深度神经网络进行强化学习(RL)的研究开始引起关注,因为深度Q网络(DQN)[18]在Atari 2600游戏中展现出与人类专家相媲美的性能[4]。DQN通过使用深度神经网络来估计动作值函数,成功解决了具有高维状态输入(如原始像素)的任务。然而,DQN不能立即应用于具有高维、连续动作空间的问题,因为它通过找到最大化动作值函数值的动作来工作。为了解决具有高维、连续动作空间的问题,提出了深度确定性策略梯度(DDPG)[16]。DDPG是一种无模型和离策略算法,使用基于深度策略梯度(DPG)[23]的演员-评论家方法。通过将DQN的回放缓冲和目标网络的思想应用于演员-评论家方法,DDPG稳定了学习过程。即使在DDPG之后,许多深度强化学习方法已被提出以改进DDPG。为了克服过度估计偏差问题,提出了双延迟深度确定性策略梯度(TD3)[9]算法。TD3通过使用一些技巧,如剪切的双Q学习和延迟的策略更新,解决了这个问题。此外,提出了Soft Actor-Critic(SAC)[12]来处理复杂环境的问题。SAC通过将熵最大化项添加到标准最大奖励强化学习目标中,显著提高了探索性能和稳定性。
提出的方法
在本节中,我们将介绍我们的方法,即基于强化学习的黑盒模型逆向攻击(RLB-MI)。RLB-MI的概述如图1所示。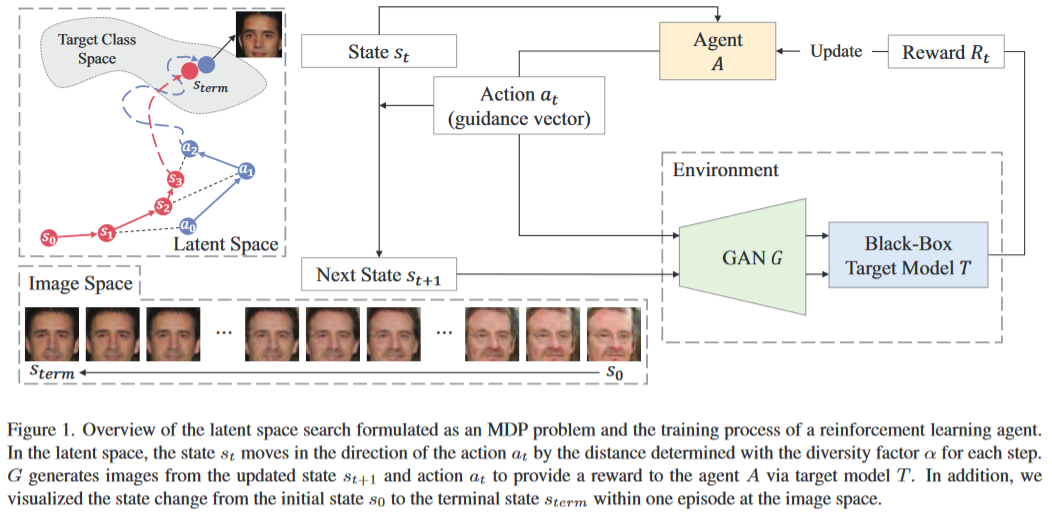
问题描述
攻击者的目标:模型逆向的目标是从使用数据集$D_{pvt}$训练的模型$T$中恢复出类别$y$的样本。目标模型$T: x\to [0,1]^K$学习的是样本到类别的映射。用$K$表示$D_{pvt}$的大小,$d$表示输入的维度。
攻击者的知识:由于我们的方法处理的是黑盒设置,攻击者只能访问由攻击者输入的数据和与数据相对应的软标签组织的查询。此外,攻击者了解目标模型的目的。正如先前的研究中所提到的[2, 5, 14, 25, 27],提供的模型或服务的任务信息不仅是可用的,而且还可以从输出的类别中轻松推断出来。基于对任务的这种了解,攻击者可以访问相应任务的公共数据集。
概述:给定在私有数据集$D_{pvt}$上训练的黑盒模型$T$,一个黑盒的模型逆向攻击目的就是恢复出这个私有的数据集。和最近的模型逆向攻击一致,我们也使用了一个公开数据集$D_{pub}$训练了一个Gan $G$。攻击者只能知道一个模型输出的软标签,但对模型的参数和结构一无所知。因此,我们的方法就是通过搜索能够使模型输出相应类别的高置信度样本的隐向量。我们把隐向量的搜索过程形式化为马尔可夫过程(MDP),然后使用强化学习来解决该问题。更具体的,我们把MDP的状态空间定义为生成器$G$的隐空间,于是每一步$t$的状态$s_t$都可以用隐空间中的向量来表示。状态$s_t$经过动作 $a_t$后会变为状态$s_{t+1}$。任务的目标就是最大化目标模型的置信度向量。
隐空间搜索中的马尔卡弗过程
我们描述了用于潜在空间搜索的MDP的组成部分:状态,动作,状态转换和奖励。
状态:MDP的状态空间就是生成器G的隐空间(输入空间)。对于每一个eposode,第一个状态$s_0$是一个$k$维的标准化随机向量:
在每一步$t$,状态$s_t$会被动作$a_t$更新。
动作:我们希望动作可以让随机产生的初始状态向着高奖励的最终状态前进。从宏观的视角来看,我们可以把这种问题理解为基于强化学习的路径查找问题。在传统的路径查找问题中,动作被定义为了$s_t$到$s_{t+1}$的位移$\triangle s$。然而,与寻路中的有界二维空间不同,潜在空间是一个不受限制的高维空间。在我们的阐述中,当将行为定义为位移向量时,由于与潜在空间相比存在较大的状态方差和狭窄的探索区域,强化学习代理可能无法收敛并达到局部最小值或完全失败。因此,我们将行为空间视为整个潜在空间。我们将一个潜在矢量形状的行为定义为一个引导矢量。如图1所示,根据定义,在相同的空间中选择行为。这使得能够广泛探索整个潜在空间,防止代理陷入局部最小值并保证代理的收敛。每一步$t$的动作都由强化代理$A:\mathbb{R}^k \to \mathbb{R}^k$来产生:
状态转移:我们通过在每一步将状态朝着行为移动来更新状态,使用一个差异因子 α 作为状态转移中当前状态的权重,以确定移动距离。在步骤 t 的状态转移如下:
我们将 $\alpha$ 称为多样性因子的原因是,我们将 $\alpha$ 提出作为一个超参数,允许我们控制生成图像的多样性。正如Wang等人所提到的[25],在重构图像时,模型逆向攻击存在准确性和多样性之间的权衡。我们可以通过 $\alpha$ 调整准确性和多样性之间的权衡。 $\alpha$ 越高,随机初始潜在向量对每个episode的影响越大,代理就越专注于生成具有高多样性的图像。例如,如果 $\alpha$ 的值为零,下一个状态将与当前步骤中的行为相同,因此代理只专注于生成目标分类器概率最高的一张图像。另一方面,随着 $\alpha$ 的增加,随机初始潜在向量的影响增大,代理被训练以找到具有高概率属于目标类别的各种图像。
奖励:在通过行为更新状态后,代理从环境中接收一个奖励。生成器 $G$ 从更新后的潜在向量生成一张图像,通过使用目标网络 $T$ 进行推理,我们可以得到图像目标类别 $y$ 的置信度分数。由于行为指导了状态的移动方向,从行为生成的图像也应该接近目标类别空间。为了将状态和行为置于靠近目标类别空间的位置,我们需要在状态和行为具有较高置信度分数时提供较高的奖励。因此,我们构建一个奖励,其中包含状态分数和行为分数,这些分数是由每个矢量创建的图像的置信度分数的对数值计算而得。这些分数的计算如下:
其中$r_1$使状态分数,$r_2$是动作分数。此外,我们希望重构的图像具有目标类别的特征,使其与其他类别的图像有所区别。因此,我们提出了一个额外的项 $r_3$,对其他类别图像的高置信度分数进行惩罚。我们计算目标类别的置信度分数与其他类别的最大置信度分数之间的差异。与先前的分数一样,对计算值应用对数。由于对于小于或等于零的数字,对数是未定义的,因此取对数为减去的值和一个小正数 $\epsilon$ 中的较大者。项 $r3$ 的表达式如下:
每一步的总奖励 $Rt$ 计算如下:
其中$w_n$是分数$r_n$的权重。
使用强化学习解决MDP
我们通过强化学习来解决被提出的潜在空间搜索问题,该问题被制定为马尔可夫决策过程(MDP)。由于所提出的由 G 和 T 组成的 MDP 的环境非常复杂,我们需要在复杂环境中具有鲁棒性的强化学习代理。此外,我们需要一个能够处理连续行为空间的代理,因为MDP中的行为空间被定义为 G 的潜在空间。因此,我们使用满足所有上述点的 Soft Actor-Critic (SAC) [12] 来解决MDP。我们训练一个SAC代理来从给定状态中选择适当的行为。在训练之后,通过将随机初始向量提供给训练过的代理作为初始状态,我们可以获得每个episode的重构图像。代理训练的整个过程如 算法 1 所示。

实验
实验设置
数据集:我们对使用代表性人脸数据集 CelebFaces 属性数据集(CelebA)[17]、FaceScrub 数据集[19] 和 PubFig83 数据集[20] 训练的目标分类器进行了攻击评估。我们将每个数据集分为一个用于训练目标分类器的私有数据集和一个用于训练生成模型的公共数据集。公共数据集与私有数据集之间没有类别交集,因此生成模型无法学习目标分类器的特定类别信息。
对于 CelebA,私有数据集包括 30,027 张属于 1,000 个身份的图像,而公共数据集包括从其余的 9,177 个身份中随机选择的 30,000 张图像,与先前的研究[5, 14]一样。对于 FaceScrub,总共 530 个身份中,随机选择的 200 个身份的所有图像用作私有数据集,剩余 330 个身份的所有图像用作公共数据集。对于 PubFig83,总共 83 个身份中,随机选择的 50 个身份的所有图像用作私有数据集,剩余 33 个身份的所有图像用作公共数据集。此外,我们使用 Flickr-Faces-HQ 数据集(FFHQ)[15] 作为公共数据集,考虑到公共数据集和私有数据集之间存在分布转移的情况。在这些实验中,从 FFHQ 随机选择的 30,000 张图像被用作公共数据集。所有人脸图像都经过居中裁剪,然后调整大小为 64 × 64。
模型:为了进行公正比较,我们尝试对几种流行的网络结构进行攻击。与先前的研究[5, 14, 27]类似,我们在实验中使用了三种网络结构,分别是 VGG16 [24]、ResNet-152 [13] 和 Face.evoLVe [6]。
评估指标:Zhang 等人[27]提出了可以定量评估模型逆向攻击的指标,与之前依赖于视觉检查的定性评估不同。我们简要描述评估指标,包括攻击准确率、K 最近邻距离(KNN Dist)和特征距离(Feat Dist)。
攻击准确率:为了评估重构图像的攻击准确率,我们在私有数据集上训练评估分类器。评估分类器必须与目标分类器不同,因为重构图像可能会过拟合目标分类器。我们使用了 Cheng 等人[6]提出的架构作为评估分类器。我们在 MS-Celeb-1M [11] 上对一个预训练的分类器进行微调,分别在 PubFig83、FaceScrub 和 CelebA 数据集上实现了 98%、99% 和 96% 的测试准确率。
KNN Dist:KNN Dist 是一种度量,用于测量重构图像的特征与目标标签图像中最近样本的特征之间的平均 L2 距离。特征是在评估分类器的全连接层之前获取的。
Feat Dist:Feat Dist 是一种度量,用于测量重构图像的特征与目标标签图像的特征中心的 L2 距离。特征是在评估分类器的全连接层之前获取的。
实验结果
基线:我们将我们的攻击性能与三个类别中包括的代表性模型逆向攻击进行比较:白盒攻击、黑盒攻击和仅标签攻击。白盒攻击的基线是 GMI [27] 和 KED-MI [5]。GMI 是使用 GAN 的第一个模型逆向攻击,而 KED-MI 在白盒攻击中表现出最高的攻击性能。黑盒和仅标签的基线是 LB-MI [26]、MIRROR [2] 和 BREP-MI [14]。为了公平比较,除了 LB-MI 和 KED-MI 之外,攻击中使用了相同的 GAN,因为 LBMI 不使用 GAN,而 KED-MI 使用其自己的生成模型,名为反演专用 GAN。我们使用每个周期的代理生成图像,并选择对目标分类器具有最高置信度分数的图像。
在各种模型上的性能评估:表1显示了RLB-MI和基线在使用CelebA训练的三个模型(VGG16、ResNet-152和Face.evoLVe)上的评估结果。每个目标模型的测试准确率分别为88%、91%和89%。尽管现有的黑盒模型逆向攻击LB-MI和MIRROR可以访问软标签,但它们的性能明显低于BREP-MI,这是一种仅标签的模型逆向攻击方法。然而,提出的黑盒攻击RLB-MI通过适当利用置信度分数的信息,远远超过了BREP-MI。此外,我们的攻击在ResNet-152和Face.evoLVe的情况下超过了最先进的白盒模型逆向攻击KED-MI,尽管无法访问梯度信息。即使在VGG16的情况下,通过RLB-MI重构的图像也捕捉到目标类的信息特征,具有与真实样本的K最近邻距离和特征距离最小。还可以看到目标分类器的更高预测性能导致攻击性能的提高。这个结果是合理的,因为性能更好的分类器包含关于训练数据特征的更准确和关键的信息。我们通过提供基线和我们的方法生成的真实样本和攻击图像,对定性评估结果进行展示,因为评估分类器可能不能完全代表人类判断。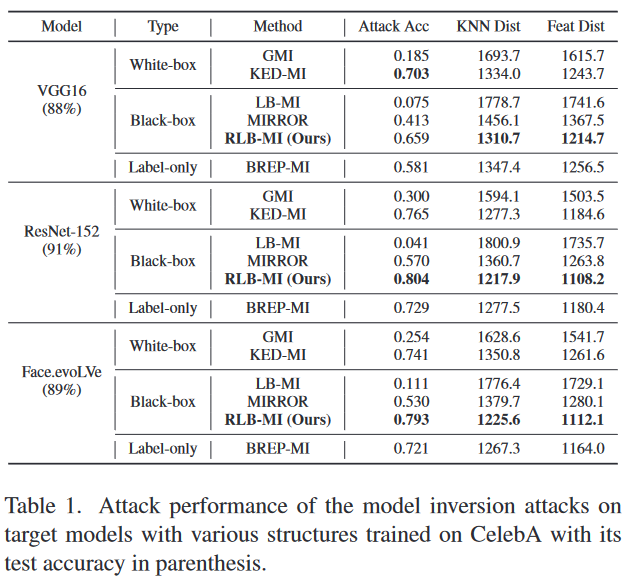

在各种数据集上的性能评估:我们测量了在使用PubFig83、FaceScrub和CelebA训练的Face.evoLVe模型上进行攻击的性能。每个目标模型的测试准确率分别为96%、97%和89%。表2显示,RLB-MI的攻击准确率优于所有基线。尽管LB-MI显示出与其他方法竞争的特征距离,但它获得了非常低的攻击准确率。这是由于LB-MI反演模型学习来自公共数据集的一般先验能力的限制引起的。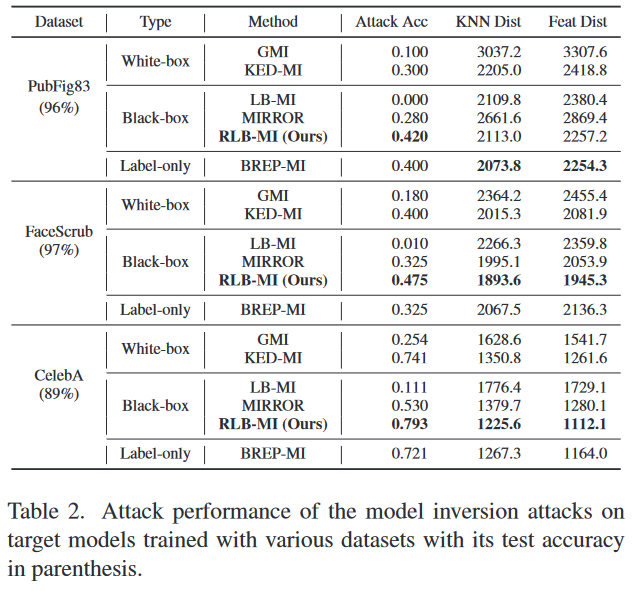
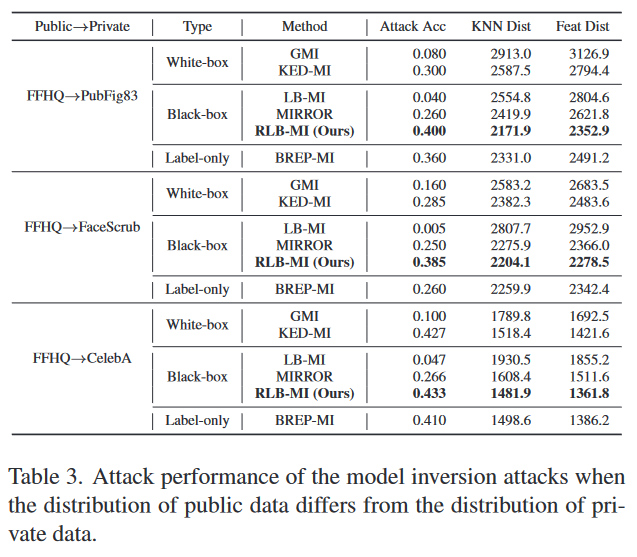
公共数据集差异的影响:在大多数实际情境中,公共和私有数据集具有相同分布的机会很少,因此我们通过在与私有数据集不同分布的公共数据集上训练生成模型来进行实验。我们使用Flickr-Faces-HQ数据集(FFHQ)[15]训练的生成模型进行攻击评估。这些实验中使用的目标分类器是使用PubFig83、FaceScrub和CelebA进行训练的Face.evoLVe。在使用FFHQ作为公共数据集的实验中,模型逆向攻击显示出了降低的攻击性能。然而,即使在公共和私有数据集之间存在分布偏移的情况下,如表3所示,我们的攻击仍然实现了最先进的攻击性能。我们认为性能下降可能是因为每个数据集中对齐或裁剪面部的方式不同,每个数据集中包含的性别或年龄分布也不同。在拍照时,由光照条件或背景引起的图像分布差异可能也会影响攻击性能。
对攻击配置进行实验
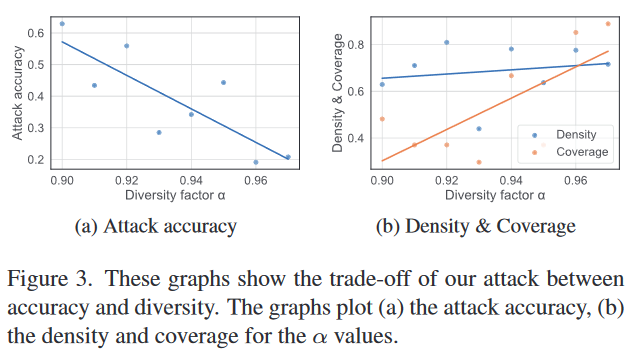
准确性和多样性之间的权衡:我们根据多样性因子$\alpha$的变化测量训练代理的攻击准确性和多样性。我们为各种$\alpha$值训练代理,并为特定身份的每个代理生成1,000张图像。为了分别评估生成图像的保真度和多样性,我们使用Density and Coverage (D&C) [3]作为度量标准。在这些实验中使用的目标分类器是使用CelebA对Face.evoLVe进行训练的。图3显示了攻击准确性和多样性之间的权衡。随着$\alpha$的增加,攻击准确性减小,表示多样性的覆盖率增加。此外,从图3b可以看出,密度对$\alpha$的变化具有鲁棒性,这意味着代理生成的图像的保真度不受$\alpha$变化的影响。当$\alpha$为0.00和0.97时生成的图像在图4中可视化。
攻击性能随最大轮数的变化趋势:为了观察攻击性能随最大轮数的变化,我们按照从1,000到40,000的步长报告攻击准确性。实验结果见图5。在图5a中,我们绘制了使用CelebA训练的各种目标模型的结果,而在图5b中,我们绘制了使用不同数据集训练的Face.evoLVe模型的结果。攻击性能每达到最大轮数就迅速增加,然后趋于稳定。即使更改目标分类器的结构,当数据集相同时,攻击准确性的趋势没有显著差异。此外,目标数据集的目标类别数越少,饱和点就越早出现,之后攻击准确性由于过拟合而下降。对于有50个目标类别的PubFig83,饱和点出现在25,000轮,而对于有200个目标类别的FaceScrub,饱和点出现在36,000轮。因此,根据目标数据集设置适当的最大轮数是很重要的。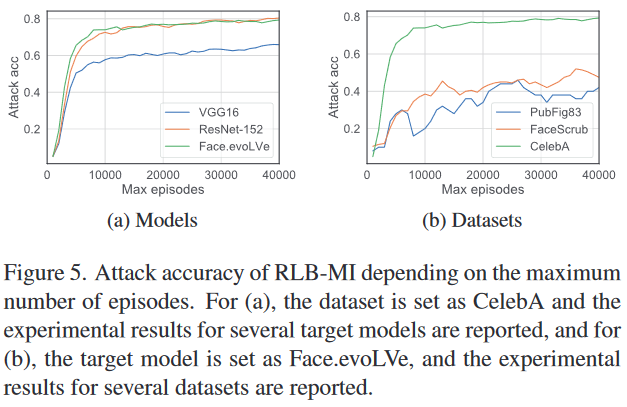
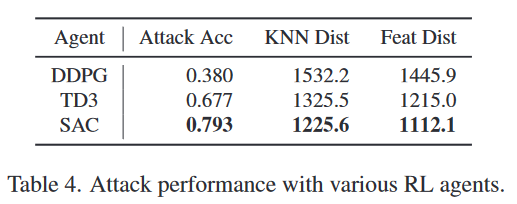
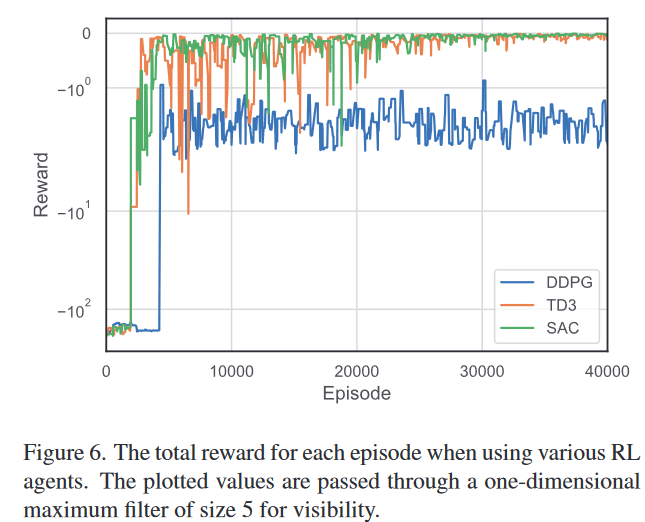
对各种RL代理的实验:为了确定RL代理的效果,我们尝试使用DDPG [16]和TD3 [9]代替SAC进行潜在空间搜索。在这个实验中使用的目标分类器是使用CelebA训练的Face.evoLVe。表4中的结果显示,当在我们的攻击中使用SAC时,其性能明显高于DDPG和TD3。我们认为这些结果的原因在于SAC对嘈杂和复杂环境的鲁棒性。在我们的攻击中,每一轮都会重新给出一个高维随机潜在向量,而目标身份的置信度对这样的潜在向量变化非常敏感。因此,对于嘈杂和复杂环境具有鲁棒性的强化学习算法,如SAC,是可取的。此外,我们在图6中展示了每个RL代理的奖励变化。
伦理的考虑
如果恶意用户滥用所提出的黑盒模型逆向攻击,可能会带来侵犯需要保护的个人信息等负面社会影响。然而,揭示当前系统的漏洞对于安全性的发展是不可或缺的。通过这项研究,我们提高了对机器学习隐私问题的关注,并敦促社区开发算法或系统以防范所提出的漏洞。我们相信,我们的工作将在安全性方面产生积极的影响,其益处将超过潜在的风险。
结论
我们提出了一种基于强化学习的新型黑盒模型逆向攻击,利用生成对抗网络(GAN)。我们将潜在空间的探索问题形式化为马尔可夫决策过程(MDP)问题,并训练一个强化学习代理来解决MDP,即使缺乏关于目标模型的信息,如权重和梯度。所提出的攻击解决了先前黑盒攻击存在的问题。此外,实验结果表明,我们的攻击成功地重构了目标模型的私有数据。我们的攻击不仅优于最先进的黑盒攻击,还优于所有其他方法,包括白盒和仅标签攻击。我们希望这项研究能够推动对黑盒模型逆向攻击和防御的研究。

