论文研读笔记(2-3页)
论文题目:Watermark Stealing in Large Language Models
发表时间:2024
发表期刊/会议:ICML (CCF A)
1. 内容简介(简要概括文章,不可以直接翻译摘要)
部署在网络中的LLM可能通过替换文本的方式在模型的输出中注入水印。水印的用途有知识产权保护和AI文本检测等。本文设计了一个模型水印窃取攻击,即训练一个本地的模型水印策略,使其水印添加方式和目标模型一致。本文还设计了两个下游攻击:水印伪造和水印擦除。
2. 主要贡献(记录文章最核心的思路、方法)
2.1 标记
| 记号 | 含义 |
|---|---|
| $T_t$ | LM第$t$步的输出 |
| $H$ | 哈希函数 |
| $\xi$ | 被攻击者所持有的水印密钥 |
| $V$ | 词库 |
| $f$ | 伪随机函数PRF |
| $l$ | logit向量 |
| $\mathcal{P}$ | 幂集 |
2.2 水印添加算法
大语言模型的水印添加方式本质上就是词替换。本文主要攻击的是目前最新的几种水印添加算法。下面对这几种算法进行简单介绍。
- KGW-Soft/Hard:假设$T_t$是第$t$步模型的输出,该算法首先把上一步输出的哈希值$H(T_{t-1})$和一个密钥$\xi$作为随机数种子,利用伪随机函数$f$将词库$V$划分为$V_{green}$和$V_{red}$ 。soft版本的算法通过增加green词的logit来增加该类词的输出概率,而hard版本的算法则是禁止输出red词($l_T=-\infty\quad for\quad T \in V_{red}$)。
- KGW2-SELFHASH:在前面工作的基础上,水印算法产生了几种变体。第一个是让PRF的输入中包含更长的上下文内容$T_{t-h},\dots,T_{t-1}$;第二个是self-seeding,即PRF的种子中引入了$T_t$本身,如果生成的$T_t$不在$V_{green}$中则拒绝采样。KGW2-SELFHASH使用h=3和self-seeding,种子的计算方式为$min\{H(T_{t-h},\dots,H(T_{t-1}),H(T_t)\}\cdot \xi \cdot H(T_t)$ 。
- KGW2-SUM:h=3, 种子计算方式为加和。
- Unigram 水印:h=0,即只使用$\xi$产生$V_{green}$ ,且固定不变。
为了检测输出是否加盖水印,需要逐个统计该输出中存在的green词个数,然后计算z-统计量$z=(n_{green}-\gamma L)/\sqrt{L\gamma(1-\gamma)}$ ,最后利用假设检验计算p值判断水印是否存在。
2.3 攻击者能力
- 水印检测器访问权限。有些模型提供了检测API,可以返回一个bit指示某段话是否加盖了该模型的水印。攻击者可以利用该API检验攻击的有效性并指导攻击的进行。
D0:没有API访问权限。前人工作大多采用此场景 D1:有API访问权限。这也符合现实场景。SynthID提供了类似的API - 基模型输出的访问权限。即攻击者是否可以收集目标模型未部署水印算法时的输出语料(不一定是水印输出的未水印版本)。
B0:不可以 B1:可以
该论文可以在上述四种场景中进行攻击
2.4 攻击算法
该攻击算法遵循Kerckhoffs原则,即假设攻击者知道被攻击者所使用水印的所有细节,除了密钥$\xi$。
该论文的攻击并不直接窃取$\xi$的具体数值,而是在给定待判定文本时,从中截取出一个序列$T_1,T_2,T_3,T$,计算一个得分函数$s(T|ctx)$,该分数指示了上下文ctx存在的情况下,生成的$T$在$V_{green}$中的置信度。为了得到该得分,攻击者首先需要计算目标模型的条件分布$\hat{p}_w(T|ctx),\quad \forall ctx \in \mathcal{P}(\{T_1,T_2,T_3\})$和一般模型的条件分布$\hat{p}_b(T|ctx)\quad \forall ctx \in \mathcal{P}(\{T_1,T_2,T_3\})$。这个条件分布指示了上下文存在的情况下模型下一步生成$T$的概率。一般模型可以为$B_1$场景下的基模型,也可以为攻击者的私有模型$LM_{att}$。s函数表示如下:
稀疏性挑战:为了降低计算复杂度,如果$\hat{p}_w(T_4|ctx)$ 和 $\hat{p}_b(T_4|ctx)$只从较少的样本计算得出,则直接将其置为0。
3. 实验结果(仅记录关键结果,重点在于对实验的分析)
正文的实验环节主要介绍最严格场景(D0,B0)时攻击KGW2-SELFHASH的结果。
攻击者在访问目标模型时使用的数据集为C4数据集的RealNewsLike子集,最终获取了长度小于800的30000个回答。c设置为2。
两个关键指标:水印强度和文本质量。对于文本质量,使用GPT4对生成文本的准确性和一致性进行打分,如果较低则水印伪造失败;使用P-SP评分估计生成文本是否完全捕捉了原文内容,如果较低则水印去除失败。
文章将两个目标合并为一个成功率指标。对于水印伪造攻击,报告FPR@f,即成功被假阳率为f的水印检测器检测为带有水印的生成样本的比例(忽略GPT分数小于6.5的样本);对于水印去除攻击,报告FNR@f,即被假阴率为f的检测器检测为不带水印的转译样本的比例。
伪造攻击的攻击结果如下(PPL好像是一种对话质量评价指标,文中没有解释。p-val即为前文水印添加算法中介绍的假设检验的p值)。该实验使用了不同的($LM_{mo}$ , $LM_{att}$)组合。结果现实,即使在低假阳率设置下,该文的方法仍然可以实现高质量文本的伪造。尽管之前认为KGW2-SELFHASH可以防止伪造,但该文方法明显做出了突破。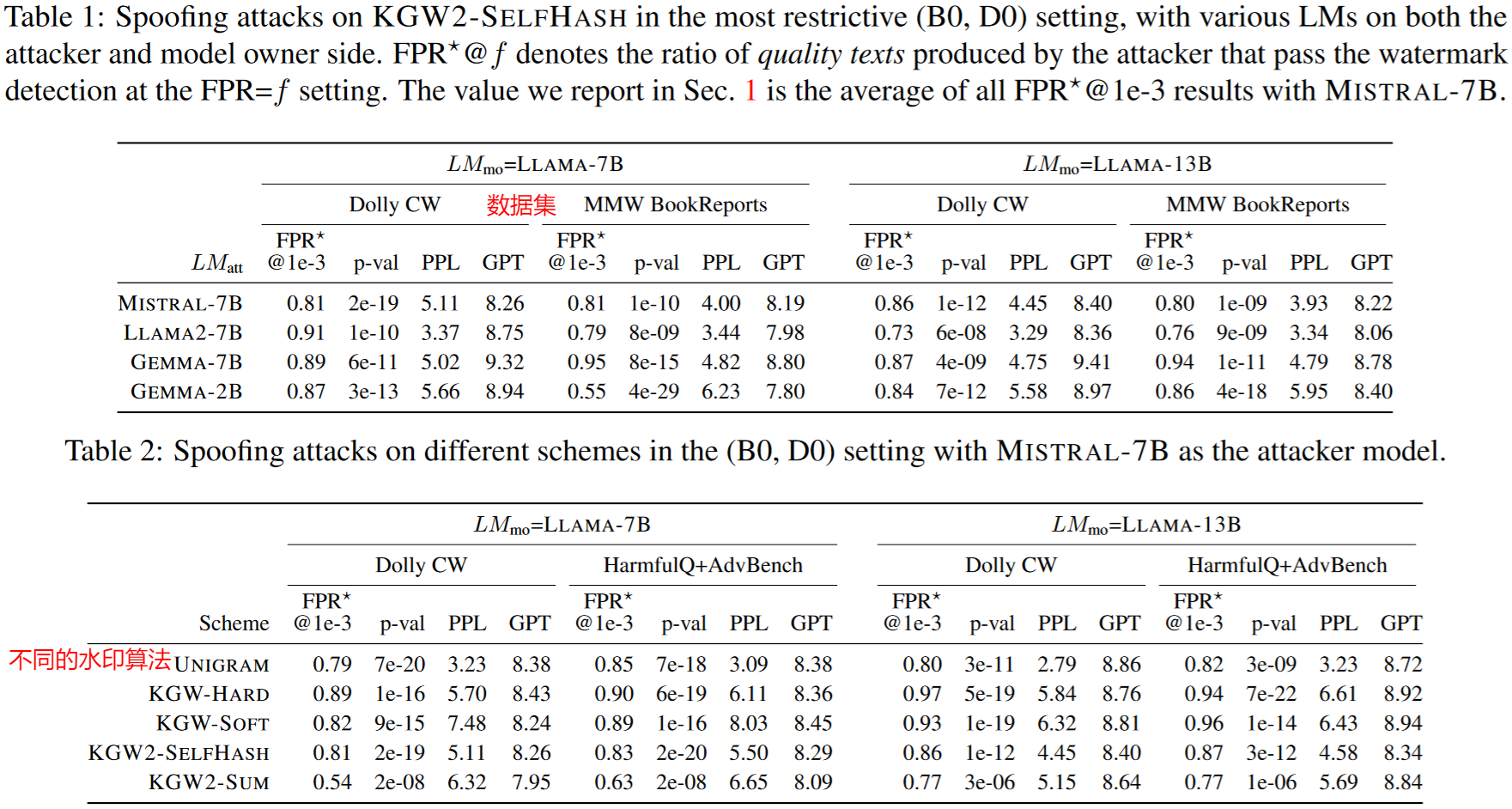
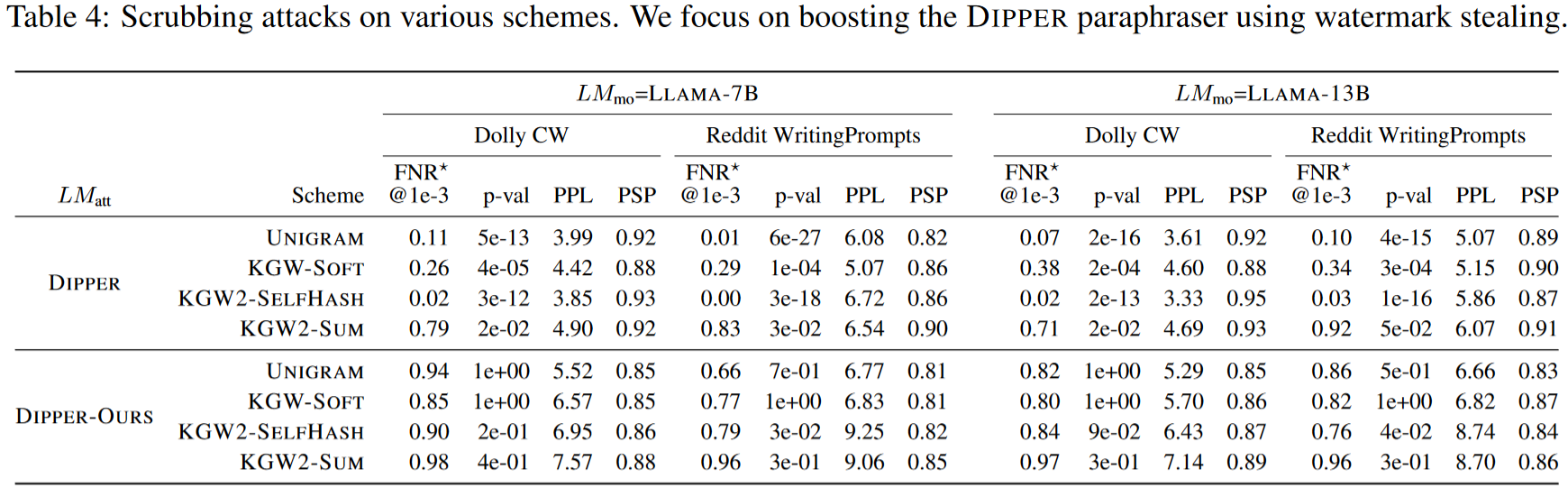
水印抹除效果提升效果如下。可以看到使用本文的水印窃取算法可以明显提升DIPPER的抹除效果。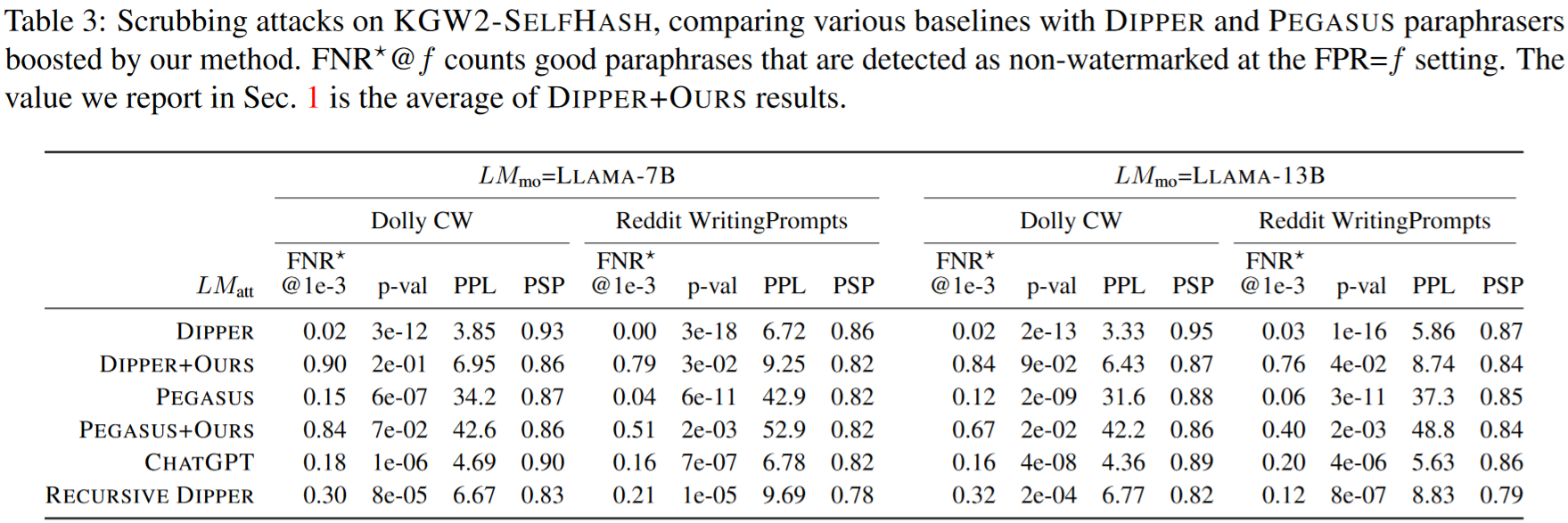
4. 写作技巧(文章在章节划分、遣词造句方面的特点)
详细的介绍了现有的最新水印算法,新手不用再翻别的论文也可以有一个大致的了解。
但部分关键内容还是不太好理解
5. 结论收获(总结自己通过本文学到的知识)
主要了解了一些最新的LLM水印算法,以及窃取水印的新思路。
了解到了Kerckhoffs原则,在某些问题里可以不给自己加太多的限制。

