论文研读笔记(2-3页)
论文题目:A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly
发表时间:2024
发表期刊/会议:High-Confidence Computing 期刊 引用量可观
笔记作者:Yifan Yao et al.
1. 内容简介
本文为大语言模型安全领域的综述。主要涉及三个方面:
- Good: AI for security,即使用LLM进行隐私保护、代码审查等
- Bad:使用LLM进行攻击
- Ugly:LLM本身的安全问题
2. 主要内容
2.1 LLM对安全和隐私的积极影响
2.1.1 代码安全性
安全编写代码:主要介绍在安全代码编程(生成)的背景下使用LLM。研究发现使用LLM辅助编写代码并不会严重增加安全隐患。后续有人提出SVEN提升模型生成代码的安全性;提出SALLM评估LLM生成代码的安全性。
测试用例生成:LLM可以成功生成测试用例,也可以用来帮助提升模糊测试的覆盖率。
脆弱代码检测:研究表明GPT-4 识别的漏洞数量大约是传统静态代码分析器的四倍。但也有研究表明LLM具有较高的误报率。现在有一些研究者将LLM和高级机制结合到一起,大大提升了检测性能。如一种二进制污点分析方法LATTE超越了现有的先进技术,而且成本更低。
恶意代码检测:研究表明基于LLM的恶意代码检测可以补充人工审查(但无法完全取代)。一个使用LLM进行恶意代码分析的工具Apiiro。
漏洞修复:多篇论文提出LLM可以有效的修复代码漏洞。而且Pearce等人观察到即使LLM没有经过专门的训练也可以修复代码。
2.1.2 数据隐私和安全
数据完整性:主要确保数据在其生命周期中保持不变且未被损坏。一些研究探讨了使用LLM制定勒索软件网络安全策略,还有一些研究使用LLM检测异常行为。
数据机密性:一些研究使用LLM将文本中的身份标记替换为通用标记,也有研究使用ChatGPT实现密码学算法。
数据可靠性:使用ChatGPT检测包含钓鱼内容的网站,具有较高的召回率和精准率。也有研究将其用于钓鱼邮件的检测。
数据可追溯性:指在单一系统或跨多个系统内追踪和记录数据的来源、流动和历史的能力。一些工作使用ChatGPT帮助分析操作系统日志等文件,也可以用来创造逼真的蜜罐来诱骗攻击者。水印技术也被应用于LLM帮助人们监控内容的使用。
2.2 LLM对隐私和安全的消极影响
硬件层面攻击:通过LLM分析物理系统或实现过程中非故意泄露的信息来推断秘密信息。
操作系统层面攻击:LLM可以分析从操作系统收集到的信息。有研究建立了一个LLM和易受攻击的虚拟机循环,LLM会分析虚拟机状态,识别漏洞并提出具体的攻击策略,这些策略会在虚拟机中自动执行。
软件层面攻击:LLM可以知道攻击者部署恶意软件。也有研究展示了如何诱骗ChatGPT生成勒索软件。
网络层面攻击:LLM可以用于网络钓鱼攻击。可以使用LLM修改邮件内容,使其更具说服力。
用户层面攻击:主要包括造谣、社会工程、学术不端、欺诈等
2.3 LLM的脆弱性和威胁
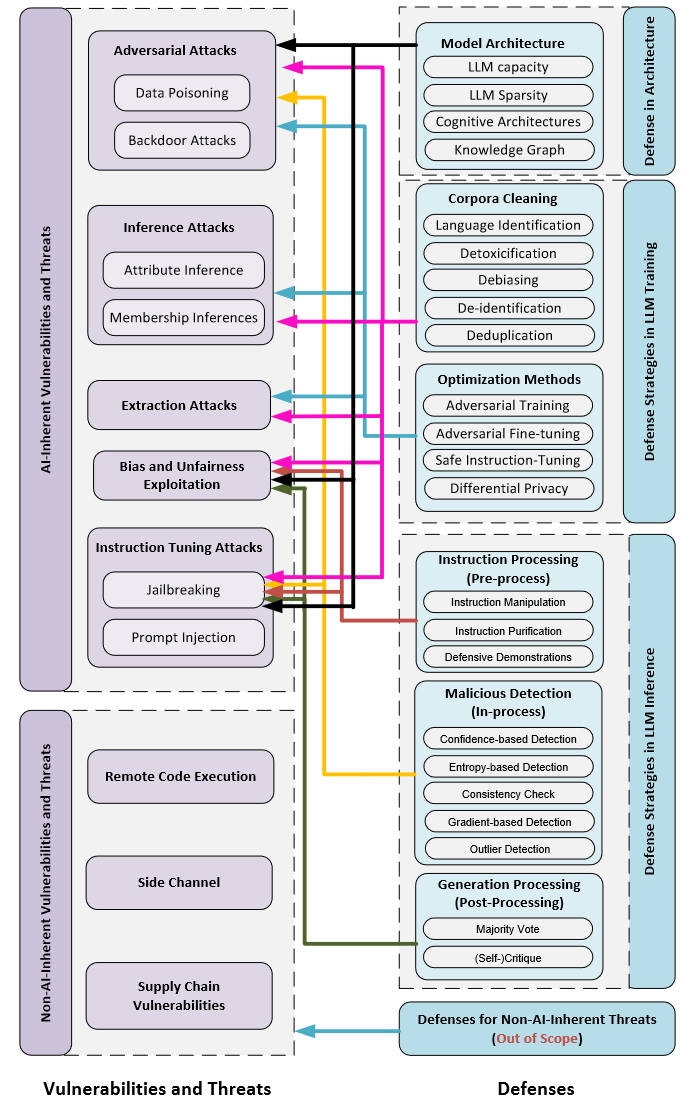
2.3.1 脆弱性和威胁
首先是AI固有的脆弱性:
对抗攻击: 包括数据投毒和后门等。
推理攻击:属性推理、成员推理等。
萃取攻击:旨在直接获取特定资源(例如,模型梯度、训练数据等)或机密信息。目前观察到训练数据提取攻击可能对LLMs有效,它是一个攻击者试图通过策略性地查询机器学习模型,从模型的训练数据中检索特定的个体样本的方法。
偏见与不公平的利用:LLM可能表现出带有偏见的结果或歧视性行为的现象。
指令微调攻击:指令微调攻击指的是针对经过指令微调的LLM的一类攻击或操控行为。这些攻击旨在利用那些使用特定指令或示例进行微调的LLM中的漏洞或局限性。包括:
- 越狱攻击:指绕过安全功能,使其能够对本应受限或不安全的问题做出回应,从而解锁通常受安全协议限制的能力。
- 提示注入:一种操控LLM行为的方法,以引发意外且可能有害的回应。此技术通过设计输入提示,绕过模型的安全措施或触发不良输出。
- 拒绝服务攻击:利用大模型耗费资源多的特点,利于攻击者进行DoS攻击。
接着介绍非AI固有的漏洞:
远程代码执行:如果LLM集成到网络服务中且该服务的的底层技术设施或者代码存在RCE漏洞,可能导致LLM环境的安全性受损。
侧信道攻击:有研究利用侧信道攻击快速提取了隐私信息,该研究提出了覆盖整个机器学习模型生命周期的四种测信道攻击。
供应链攻击:LLM可能因为使用供应链的不安全插件、数据、预训练模型导致产生新的安全隐患。大多数此类攻击研究的是LLM插件的安全性。
2.3.2 防御
基于模型架构的防御:模型架构决定了知识和概念是如何存储、组织和上下文交互的,这对于大型语言模型的安全性至关重要。研究表明使用较大参数的模型可以更好的以差分隐私的形式进行训练。也有研究表明可以将多种认知架构融入LLM来提高人工智能的鲁棒性。同时也有研究者利用知识图谱增强LLM的推理能力,从而建立对AI的信任关系。
模型训练时的防御:
- 语料清洗:LLM的训练数据质量对LLM安全性有着很大的影响。网络上收集的语料被认为有不公平、有毒性、不真实、侵犯隐私等缺陷,目前有大量工作为清洗数据做贡献。主要流程有:语种识别、去毒、除偏、隐私去除、去重等。
- 优化方法:优化目标对于指导LLM如何从训练数据中学习,影响哪些行为受到鼓励或惩罚至关重要。主要方法有:对抗训练、鲁棒微调
模型推理时的防御:
- 指令处理(预处理):对用户发送的指令进行处理,去除其中潜在的破坏性行为。指令预处理方法有:指令篡改、净化、防御性演练等。
- 恶意检测(执行中处理):提供了对LLM中间结果(如神经元激活情况)的深度检查,如利用掩码敏感度区分正常指令和中毒指令;根据可疑词的文本相关性识别可疑词;根据多代之间的语义一致性来检测对抗样本。除了LLMs的内在特性外,还有一些工作利用了语言统计特性,例如检测离群词。
- 结果处理(后处理):检查模型输出并在必要时进行修改。可以通过比较多个模型输出来降低输出毒性,也可以使用另一个单独的LLM来检查输出的危害性。
3. 结论收获(总结自己通过本文学到的知识)
LLM安全研究现状,了解到了一些前沿的研究点

