论文研读笔记
论文题目:OSLO: One-Shot Label-Only Membership Inference Attacks
发表时间:2024
发表期刊/会议:To appear at NeurIPS 2024
1. 内容简介
在只能访问目标模型一次的前提下提出了一种新的Label-only成员推理攻击方法。在低假阳率的前提下,该方法和其它Label-only方法进行对比,获得了很大的性能提升。该论文还测试了多种不同的防御方法对该攻击的防御性能。
2. 主要内容
2.1 攻击者能力
- 攻击者只能访问目标模型一次
- 攻击者不需要知道目标模型架构
- 攻击者可以拥有同分布的数据
- 攻击者只有黑盒访问权限,且只能获得模型返回的标签
2.2 攻击Intuition
成员样本和非成员样本在面对对抗扰动时有两种现象:
- 从整体平均来看,成员样本相比非成员样本需要更大的扰动
- 对于每个单独的样本来说,成员样本需要更大的扰动。
没看懂这俩有啥区别
前人工作只利用了第一条,而改论文利用了第二条
2.3 攻击方法
整体的攻击思路分为三步:
- 生成源模型和验证模型:攻击者利用手头多余的数据训练多个不同架构不同训练集的代理模型,并将其分为源模型和验证模型。源模型用来生成对抗样本,验证模型用来验证对抗效果
- 利用源模型生成对抗样本:攻击者利用代理模型生成待推理模型的对抗样本。每个样本尽可能少添加扰动,使其恰好将验证模型的预测置信度降到某个阈值下即可
- 利用对抗样本的可迁移性测试生成的对抗样本能否绕过目标模型。如果可以绕过则判定其为成员
对抗样本生成的算法如下图所示。和一般的对抗样本生成算法的区别在于该算法利用迭代不断的扩大扰动大小限制,直到刚好可以让模型置信度降到阈值以下。

3. 实验
3.1 实验设置
使用cifar10/100、SVHN数据集,ResNet18 、 DenseNet121模型。使用目前最好的五种label-only攻击作为baseline。使用真阳率、假阳率、精准率、召回率作为评价指标。主要关注低假阳率的区间内真阳率的表现。
3.2 实验结果
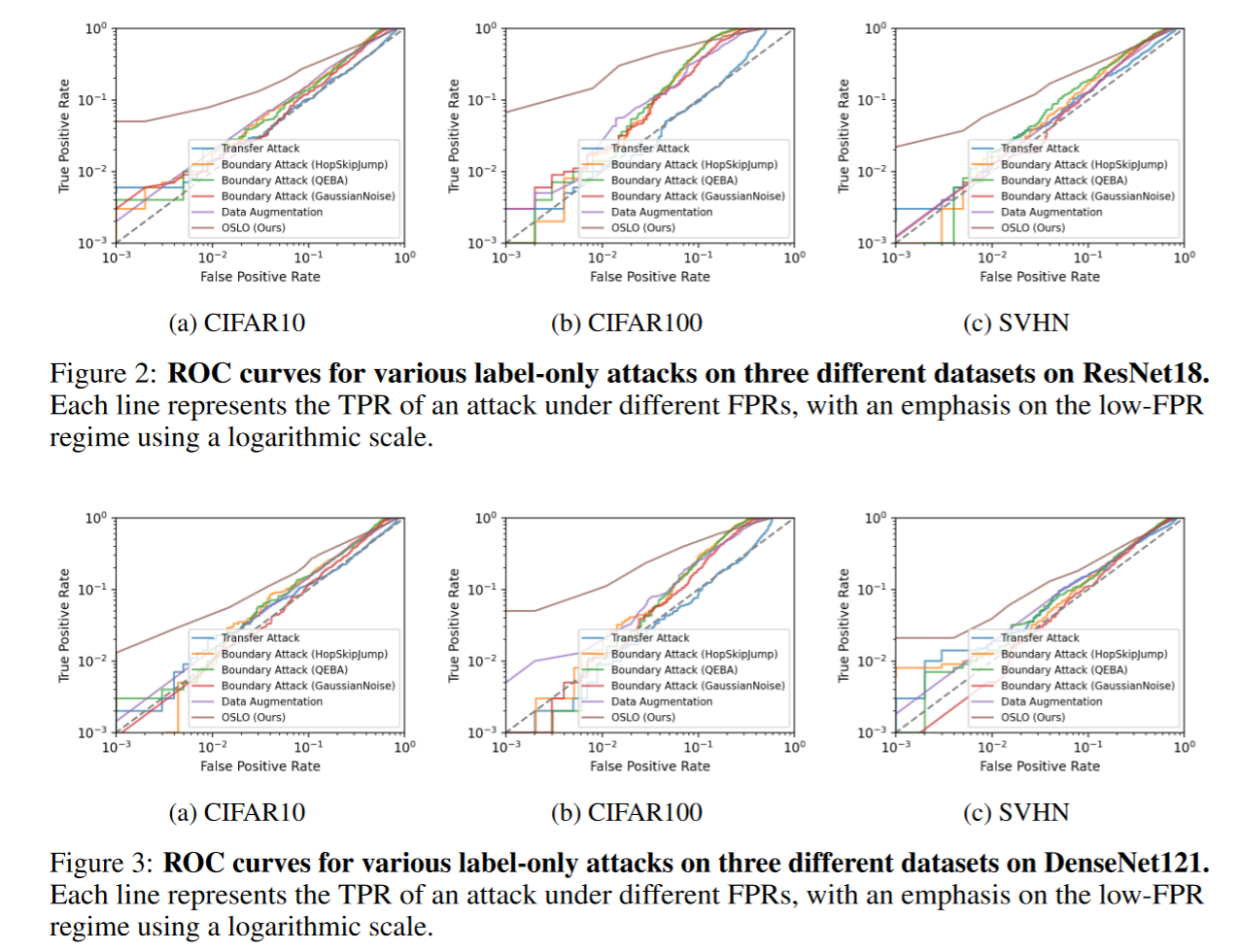
低假阳率区间内真阳率表现
如下图所示,OSLO 在性能上大幅优于此前的所有仅标签成员推断攻击(MIAs)。例如,与之前的攻击相比,OSLO 在 ResNet18 上的 0.1% FPR 下,TPR 提高了 5 倍至 67 倍;在 1% FPR 下,TPR 提高了 3 倍至 16 倍(评估于三个数据集)。在 DenseNet121 上,1% FPR 下的提升范围为 2 倍至 12 倍。可以观察到,以往的攻击在低 FPR 区间表现不佳,而 OSLO 即使在低 FPR 下也能成功识别部分成员。例如,在 CIFAR-100 数据集上使用 ResNet18 时,0.1% FPR 下,其他最好的仅标签 MIA 的 TPR 仅为 0.3%,而 OSLO 达到了 6.7%。在 1% FPR 下,OSLO 的 TPR 为 18.9%,而其他攻击最高仅能达到 2.7%。
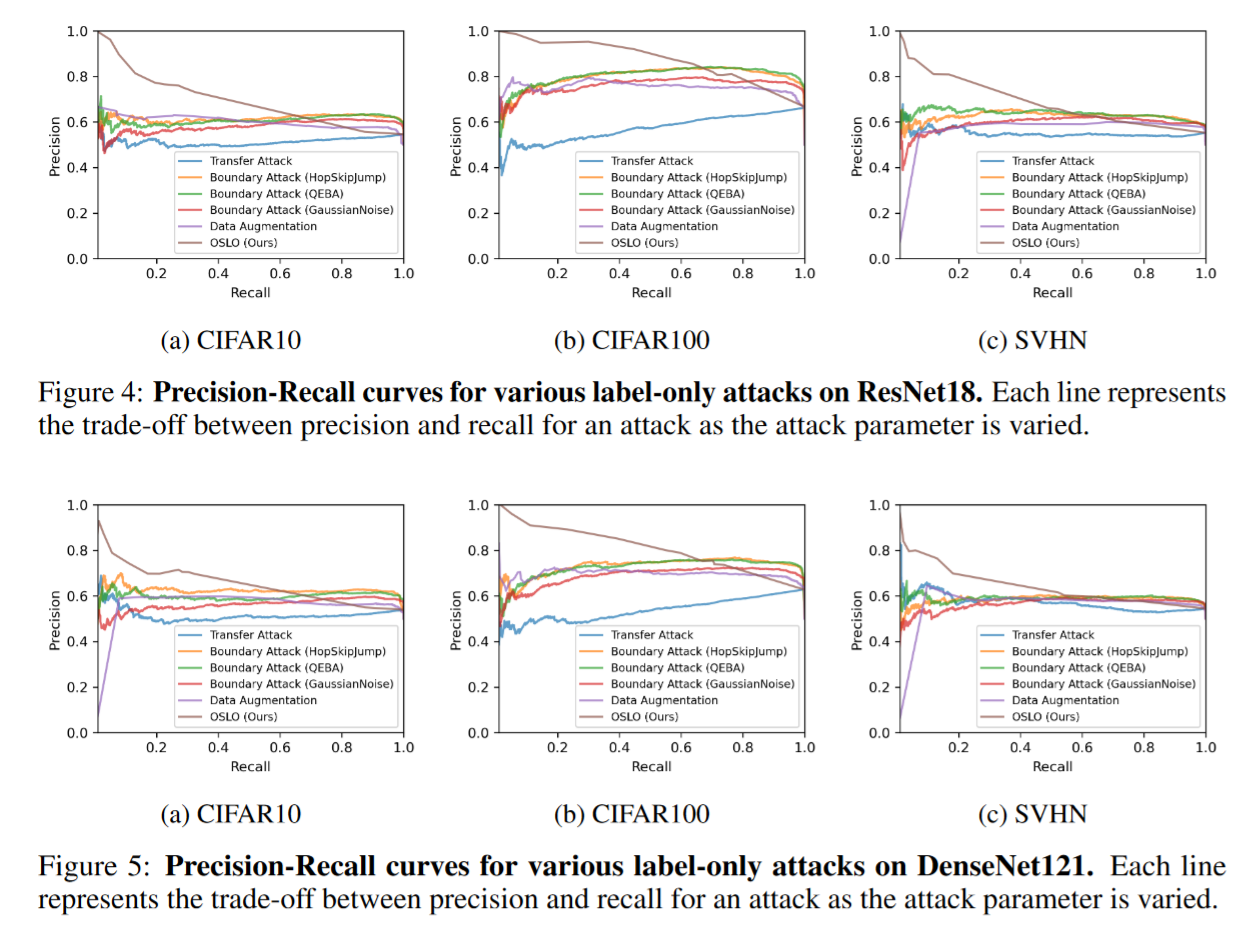
精准率和召回率分析
如下图所示,OSLO 是唯一能够有效在召回率与精度之间进行权衡的攻击方法。例如,通过牺牲召回率,OSLO 在以 ResNet18 为目标模型的所有三个数据集上都实现了 90% 以上的精度。具体而言,在 CIFAR-10、CIFAR-100 和 SVHN 数据集上,当召回率分别为 5%、44.7% 和 9% 时,OSLO 达到了 96.2%、92.0% 和 90.9% 的精度。相比之下,在相似召回水平下,其他攻击方法的最高精度仅为 67.4%、82.5% 和 65.2%。这表明 OSLO 能够以高精度识别成员,而之前的所有仅标签攻击方法都无法匹敌。
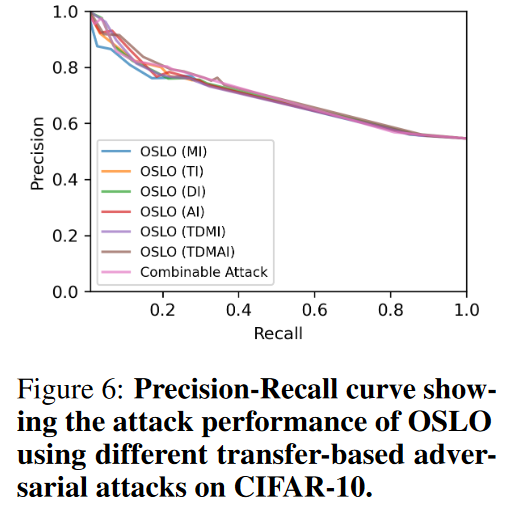
消融实验
不同对抗样本生成算法的影响:论文在 OSLO 框架内使用六种不同的基于迁移的对抗技术评估了成员推断的性能,包括 TI、DI、MI、Admix以及可组合方法 TDMI 和 TMDAI。结果显示这些改变对攻击性能影响不大。说明攻击成功的原因是框架设计的成功。
本地代理模型训练算法的影响:代理模型使用和目标模型不同的优化算法,得到结果如下表。可见即使优化算法不同对结果影响也不大。

测试验证模型的影响:移除验证模型,使用统一的扰动范围生成对抗样本。结果如下表。结果显示一同操作下来性能收到了严重影响。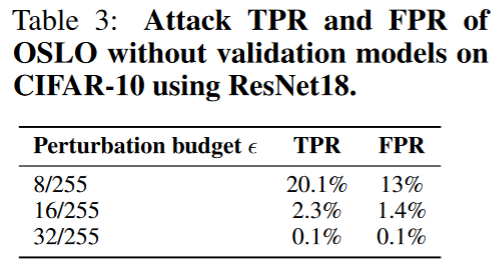
多次查询的效果:下图展示了 OSLO 在不同对抗样本生成阈值 $\tau$下的精度和召回率。n-shot表示如果所有n次对抗样本均未成功欺骗目标模型,则将样本判定为成员。论文发现增加查询次数并未带来显著提升。这一结果可以归因于以下观察:即使采用多次查询,只有最低$\tau$的那次查询结果具有决定性作用。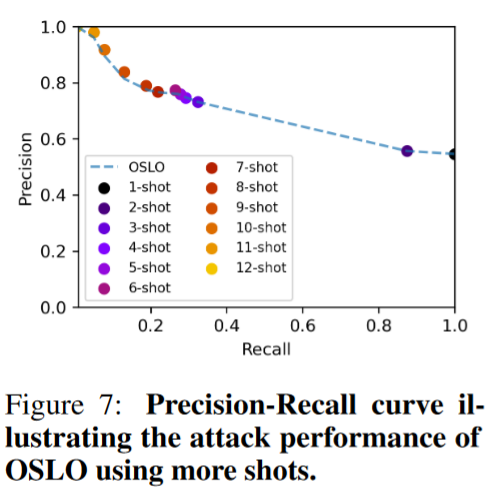
结论和收获
这篇文章介绍了一种one-shot的label-only攻击,主要攻击思路是利用本地代理模型生成对抗样本,然后利用成员样本不易产生对抗性来实现成员推理。攻击性能的提升主要得益于对每个样本进行单独的扰动大小限制。
本文的消融实验设置方法值得学习,可以作为一个模板使用。同时这篇文章还是需要攻击者获得同分布的数据,还存在改进的点。

