论文研读笔记
论文题目:Low-Cost High-Power Membership Inference Attacks
发表时间:2024
发表期刊/会议:ICML
1. 内容简介
这篇文章通过重新设计评分函数,成功实现了一种资源消耗更低、TPR-FPR曲线上表现更好的成员推理攻击。
2. 主要内容
2.1 攻击者能力
- 知道目标模型架构
- 可以拥有同分布的数据
- 只有黑盒访问权限, 需要知道输出置信度
2.2 概念框架
该论文将成员推理视为概率论中的假设检验。即存在两个假设:
攻击者被随机置入其中一个世界,他需要根据自己的知识收集足够多的证据来推断自己处于哪个世界中。
2.3 攻击方法
提出了一种新颖的统计检验方法,将原假设$H_{out}$建模为由多个世界组成,其中目标数据x被替换成其它数据点z。接着组合多个成对的(x,z)似然比检验。为了拒绝原假设,需要对z进行充分采样来证明x在训练集时能够训练出$\theta$的概率大于z替换掉x后能够训练出$\theta$的概率。数据点$x,z$的似然比定义为:
$Pr(\theta|x)$表示x在训练集时能够训练出模型$\theta$的概率。其中训练集的其余数据点由数据分布$\pi$均匀采样。
对似然比进行变形可以得到:
$Pr(x)$和$\pi(x)$的意义不同。$Pr(x)$是贝叶斯公式中的一个归一化常数。计算公式为:
其中$Pr(x|\theta’)$表示x在模型$\theta’$上的输出置信度。在实际应用中,我们通过抽样参考模型θ′来计算$Pr(x | \theta’)$的均值作为$Pr ( x )$的经验值,每个参考模型都在从总体分布$\pi$中抽取的随机数据集D上训练得到。由于只使用一小部分的数据和模型,为了得到模型参数$\theta’$的无偏采样,x应该在一半模型的训练集中。这带来很高的计算代价。为了解决这个问题,论文的离线算法只在OUT模型(训练集没有x的模型)中通过平均$Pr(x|\theta’)$计算$Pr_{OUT}(x)$,然后通过放大$Pr_{OUT}(x)$得到$Pr_{IN}(x)$。
由此,可以得到样本x的评分函数:
本论文提出的算法如下图:
3. 实验
数据集:CIFAR-10、CIFAR-100、CINIC-10、ImageNet 和 Purchase-100
baseline:Attack-P(Ye 等,2022) Attack-R(Ye 等,2022) LiRA(Carlini 等,2022)Quantile Regression(Bertran 等,2023)
测试目标:
- 在有限计算资源下训练参考模型时攻击的表现。这包括将攻击限制为离线模式,其中参考模型是预训练的。
- 当能够无限训练参考模型时(在线模式),攻击的最终能力。
- 当目标数据点是分布外数据时,攻击在区分成员与非成员方面的强度。这反映了攻击作为预言机在将整个数据空间划分为成员和非成员时的鲁棒性和实用性。
- 对手的知识对攻击性能的影响(特别是关于人群数据的分布变化,以及目标模型与参考模型之间的网络架构不匹配)。
3.1 低资源预算情况下的攻击效果
使用少量参考模型:下图显示的是当参考模型数量为1时所有攻击方法的TPR和FPR曲线。可以看到在任何情况本论文攻击(RMIA)都优于其它攻击。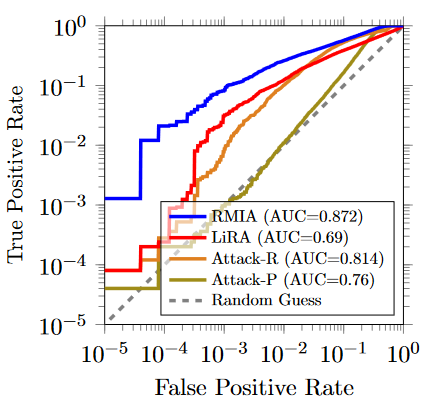
下表比较了在低成本场景下攻击的结果,结果显示RMIA在所有数据集上都严格优于其它的工作。甚至离线的RMIA攻击由于在线的LiRA,可以在低FPR的区间获得最好的效果。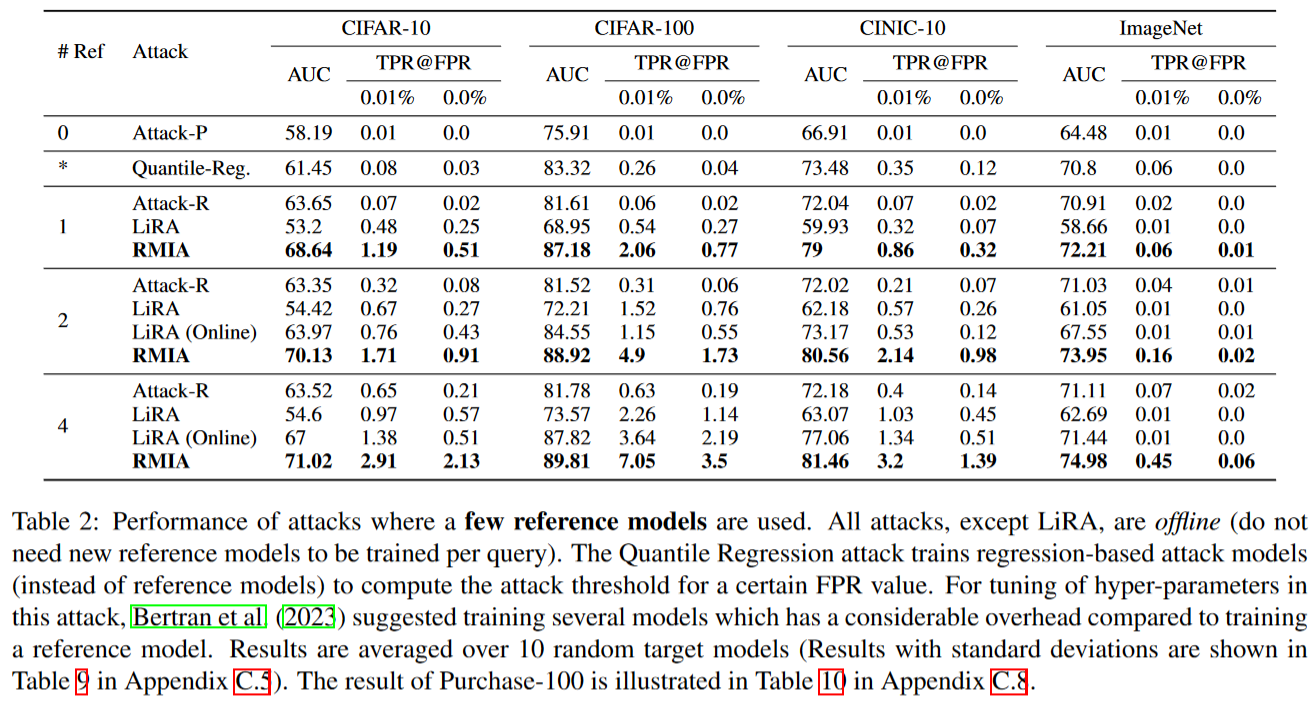
更大的模型和更大规模的数据集:模型和训练集规模增加后,攻击效果可能会下降。上表展示了当使用Imagenet作为数据集时RMIA的攻击效果对比。可以看到改论文效果优于其他攻击。
离线模式下使用更多的参考模型:下表展示了当使用更多参考模型(127个)时的对比实验情况。RMIA仍然是最好的。同时可以看到即使参考模型增多,RMIA攻击性能也没有太多的变化。说明参考模型数量对RMIA影响不大,RMIA可以是一种低资源消耗的攻击。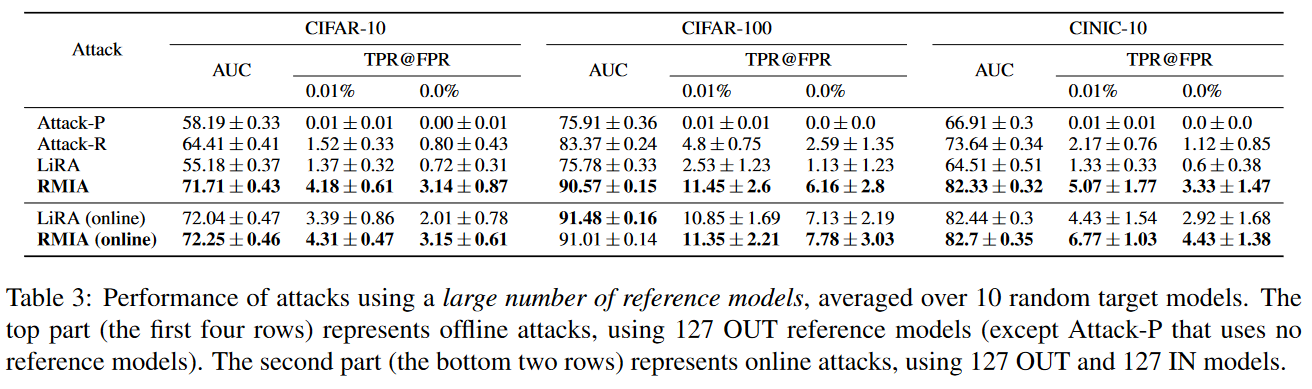
3.2 面对离群样本(OOD,Out Of Distribution)时的鲁棒性
一个强大的MIA应该可以排除所有非成员,即使他来自不同的分布。所示MIA应该在分布外数据上保持高准确性。但尽管与分布内样本相比,OOD样本通常表现出较低的置信度,但仅根据置信度进行过滤会导致算法拒绝“较难推理”的成员。
论文使用cifar10训练模型,使用CINIC-10作为OOD样本。结果如下图。可以看到RMIA具有明显的优势,而LiRA的表现和随机猜测差距不大。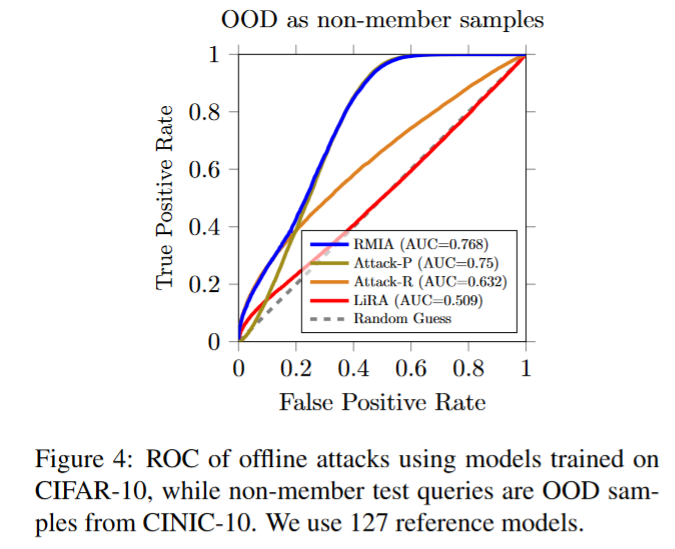
3.3 分析RMIA的参数
下表展示了使用不同数量的z样本所带来的性能变化。可以看到使用2500个样本和使用25000个样本所展现出的结果差异不大。即使只参考250个参考样本,低FPR时的TPR仍然很高。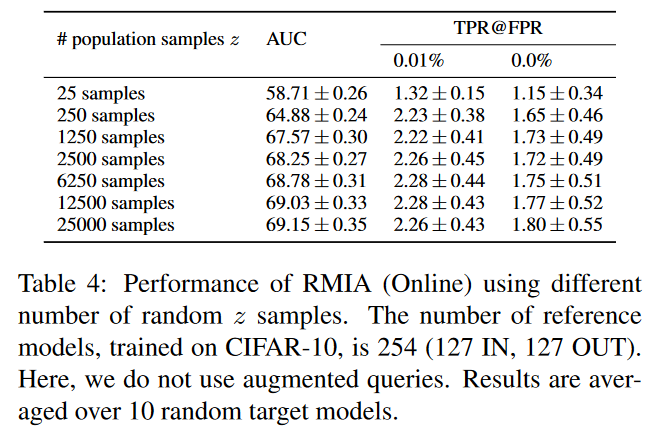
攻击其它ML算法
测试了该算法对Gradient Boosting Decision Tree (GBDT)的攻击效果。该论文算法效果一致优于其它算法。
结论和收获、
这篇论文通过重新设计评分函数,实现了一种高性能,低代价的离线成员推理攻击方法。通过和其它sota的对比,证明了它性能的优越性。
论文在实验章节的开头就介绍了后续会测试哪些实验,后续写论文可以参考。

