论文研读笔记
论文题目:Do Membership Inference Attacks Work on Large Language Models?
发表时间:2024
发表期刊/会议:COLM
论文作者:Duan et al.
1. 内容简介
论文针对大语言模型的成员推理攻击进行了广泛的测试。测试说明成员推理攻击对大语言模型的效果近似于随机猜测,并对该现象的产生做出了解释。
2. 主要内容
改论文主要通过实验验证成员推理攻击对大语言模型的有效性。假设$\mathcal{M}$是目标模型,论文考虑了如下的几种攻击方法:
- 基于损失LOSS:只要目标样本在模型上的损失小于某个阈值就判定其为成员
- 基于参考模型的攻击:如果样本在目标模型上的损失小于参考模型上的损失,就认为是成员
- Zlib entropy:使用 zlib entropy作为损失
- 近邻攻击:对样本进行变形,如果样本本身的损失小于变形样本的均值就认为是成员
- min-k% 概率:使用置信度向量中最低的k%分量计算损失
3. 实验
模型:主要针对PYTHIA模型套件,包括:(1)五个PYTHIA模型(Biderman et al., 2023b),其参数分别为160M、1.4B、2.8B、6.7B和12B,训练数据为原始的Pile数据(Gao et al., 2020);(2)五个PYTHIA-DEDUP模型(Biderman et al., 2023b),具有与PYTHIA相同的参数数量,但训练数据为去重后的Pile数据。我们还使用GPT-NEO家族的模型进行实验,以验证在不同模型家族中的发现,观察到大多数领域的趋势类似(见附录A.6)。
数据集:Pile中包含的七个多样化数据源:通用网页(Pile-CC)、知识来源(维基百科)、学术论文(PubMed Central,ArXiv)、对话数据(HackerNews)以及特定领域数据(DM Math,Github)。
评估指标:AUC, ROC,TPR@low%FPR
3.1 主要结果
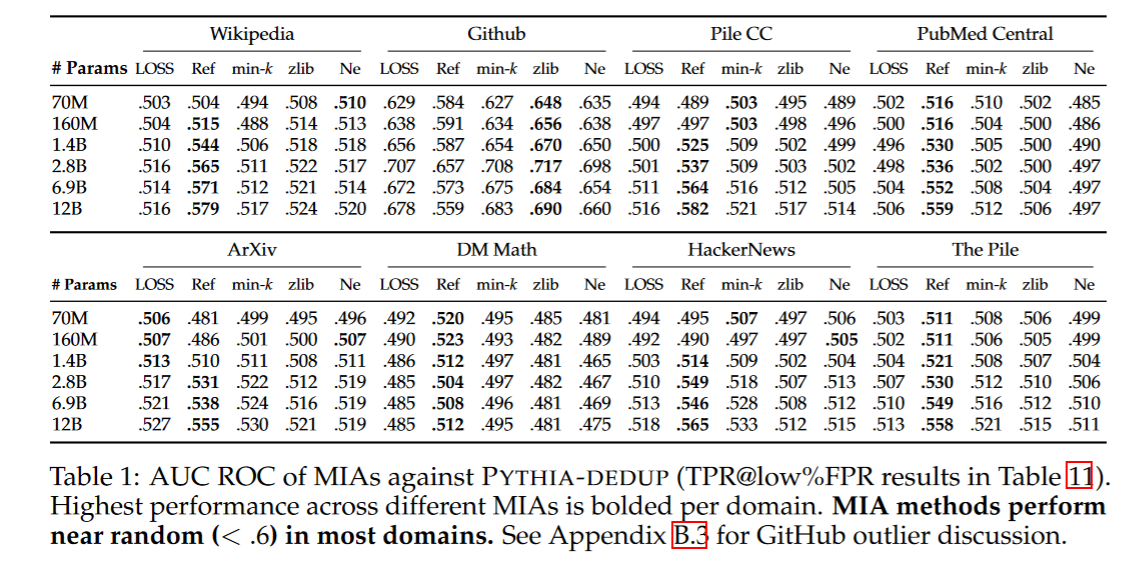
由下表可知,现在所有的针对大模型的成员推理都接近于随机猜测。总体上基于参考模型的推理表现最佳,而且发现训练集的去重降低了MIA的表现。
3.2 为什么MIA表现不佳
3.2.1 LLM的特性
训练集规模:当前最先进的大语言模型都使用巨量的数据训练模型,而模型的泛化程度会随着数据集的变大而变好。在这论文使用PYTHIA-DEDUP模型套件中的中间检查点来评估不同规模训练数据的影响。论文对每个检查点的最近100个步骤中采样成员,以去除成员的时效性偏差影响。MIA的表现一开始接近随机猜测,后来迅速升高,最后逐渐下降(如下图左)。开始性能低可能是因为模型在热身,对成员和非成员的损失都很高。后面随着训练的进行,由于数据和参数的比例较小,模型会出现过拟合。但最后随着训练的进行模型的泛化能力会加强。
训练轮次:增加训练轮次会增强MIA性能,但也会增加隐私泄露的风险(下图右)。论文对Datablations模型套件(Muennighoff et al., 2023)进行了MIA测试,该模型套件包含在不同epoch数量下,使用C4(Raffel et al., 2019)训练数据的子集训练的模型。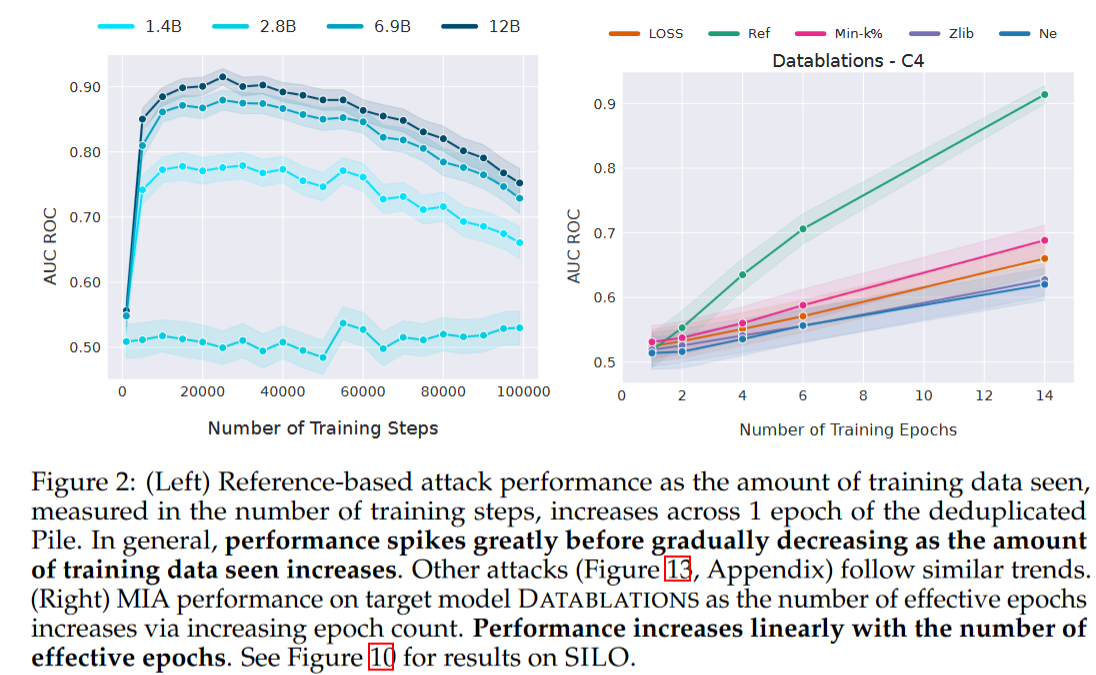
3.2.2 LLM固有的模糊性
自然语言中存在重复文本,包括相近的表达方式、相似文本的自然使用、特定领域内的固有说法等,这就导致成员和非成员之间的差异没有那么明显。论文使用n-gram重叠比来量化重叠。对于一个m个词组成的成员样本$x=x_1x_2\dots x_m$以及其中的一个n-gram$x_i\dots x_{i+n-1}$,x在数据集D上的n-gram重叠定义为:
这一指标表示非成员样本中的n-gram中有多少百分比至少能在一个成员样本中找到。下图展示了非成员样本对于整个训练集的7-gram重叠百分比。可以看到很多数据集的重叠比都很高。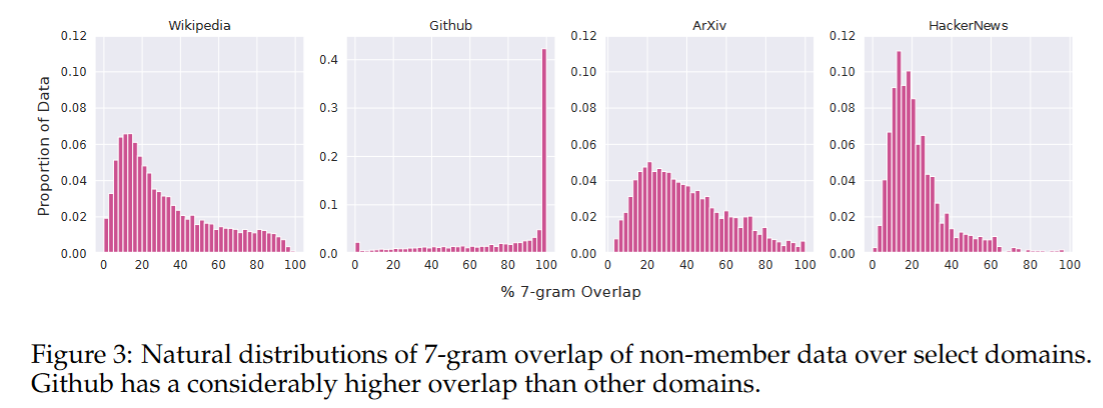
论文重新采样非成员样本,使重叠率降低,重新报告了MIA的性能。可以看到MIA的表现显著提高。
论文指出n-gram是自然语言的固有属性,还指出,n-gram重叠分布分析有助于评估一组候选非成员样本在构建MIA基准测试时,是否能代表目标领域。论文强调需要考虑数据领域的特征,例如n-gram重叠,并理解它们可能对MIA性能的影响。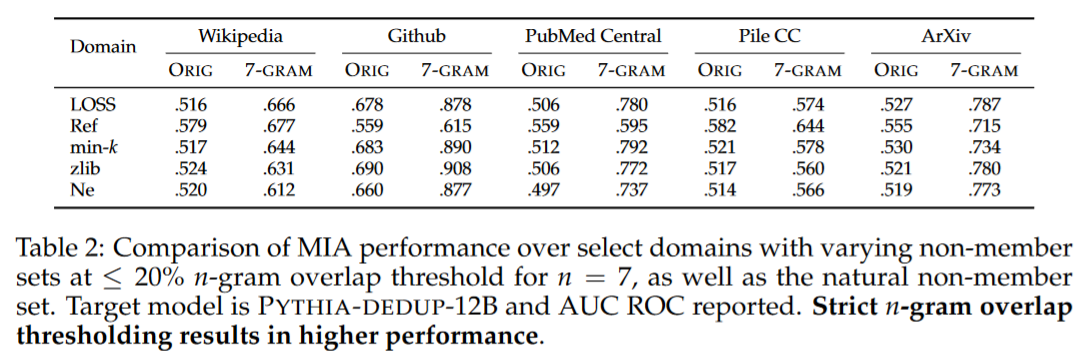
3.3 候选集选择的重要性
最近的研究表明最先进的成员推理攻击在预训练模型上达到了>0.7的AUC ROC。论文探讨了这些研究非成员候选选择方式如何导致非成员和成员之间固有、无意的分布偏移。以往的工作通常根据目标模型的知识截止日期来区分目标领域中的成员和非成员,成员为截止日期之前的样本,非成员反之。
论文在wikipedia领域进一步加大了成员和非成员之间的时间差距。下表显示该设置可以显著增强成员推理的性能。推测这是源于语言的变化,如新术语的引入。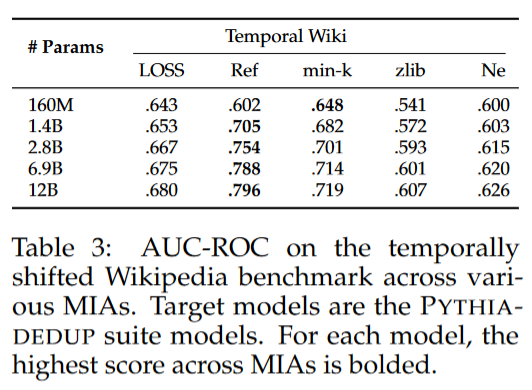
下图展示了时间偏移前后7-gram的变化。可以看到时间偏移后7-gram重叠降低。论文建议在评估MIA性能时通过将候选非成员样本的n-gram重叠分布与从预训练语料库中剔除的样本集的n-gram重叠分布进行比较,来估算样本非成员集在成员领域中的代表性。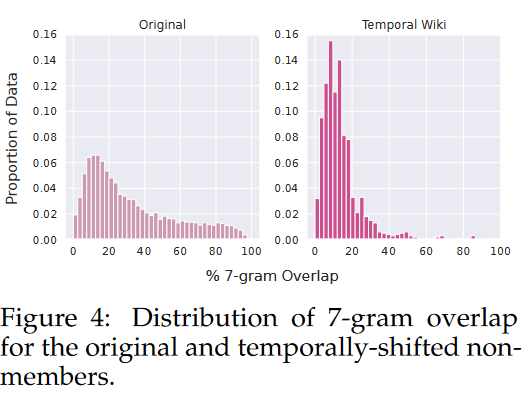
4. 结论
论文利用实验说明现在的成员推理攻击和随机猜测没什么差距。主要原因是1. 目前大模型的训练过程中使用的数据量大且训练轮次小,所以单个样本所能留下的痕迹很小;2. 成员和非成员之间具有很强的相似性(自然语料中可能包含很多重复的片段),导致他们之间的界限是模糊的。
