Are Diffusion Models Vulnerable to Membership Inference Attacks 阅读笔记
论文题目:Are Diffusion Models Vulnerable to Membership Inference Attacks?
发表时间:2023
发表期刊/会议:ICML
论文作者:Duan et al.
1. 内容简介
这篇文章通过实验说明现有的成员推理攻击对扩散模型几乎无效。同时设计了一种新的针对扩散模型的攻击方法。主演贡献如下:
- 研究扩散模型在成员推理攻击上的脆弱性。总结了传统的MIAs方法,并评估了它们在扩散模型上的表现。结果表明,这些方法大多无效。
- 提出了SecMI,这是一种基于查询的MIA方法,依赖于对前向过程后验估计的误差比较。我们将SecMI应用于标准扩散模型(如DDPM)以及当前最先进的文本到图像扩散模型(如Stable Diffusion)。
- 在多个数据集上评估了SecMI,并报告了攻击性能,包括低假阳率(False-Positive Rate, FPR)下的真阳性率(True-Positive Rate, TPR)。实验结果表明,SecMI在所有实验设置中均能准确推断成员关系,平均攻击成功率(ASR)≥ 0.80,接收者操作特性曲线下面积(AUC)≥ 0.85。
2. 主要内容
2.1 问题描述
存在两个数据集$D_M,D_H$。M表示该数据集为成员集合(member set),H表示非成员集合(hold-out set)。待推理集合$D=D_M\cup D_M$ 。攻击者需要利用攻击算法$\mathcal{M}$推理出$\forall x_i \in D,x_i$是否在$D_M$中。
2.2 分析现有攻击失败原因
- 之前攻击使用了较少的训练集,使得模型过拟合严重。
- 扩散模型拟合的更好。前面工作假设如果一个样本更容易被生成器生成则它就有可能是成员。但是这个假设只有在模型过拟合的情况下才成立,即$d\left(p_\theta, p_{D_M}\right)<d\left(p_\theta, p_{D_H}\right)$。$p_\theta,p_{D_M},p_{D_H}$分别表示的是生成器分布,成员分布和非成员分布。论文验证了25000个合成数据和25000个成员/非成员之间的距离,发现距离数值分别为9.66和9.85。说明扩散模型并不会对成员样本产生明显偏斜。
2.3 攻击方法
建立t-error评分方法。对于一个$x_0 \sim D$和它在第t步的反向结果$\tilde{x}_t = \Phi_\theta(x_0,t)$,第t步的后验估计误差为:
如下图所示,非成员集合的t-error通常更高,尤其是t接近0的时候。原因是更小的t会触发模型更多的记忆。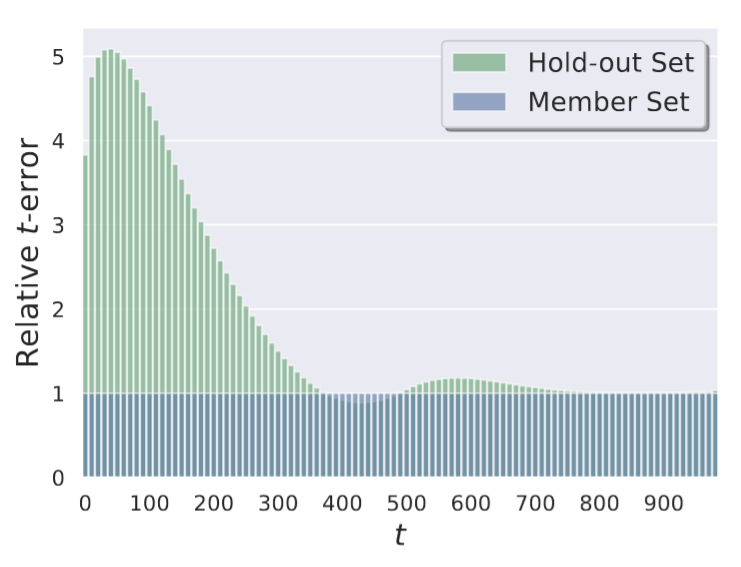
基于此,改论文设计了两种攻击方法:
- 基于统计的推理:如果t-error小于某个阈值,就将其判定为成员。
- 基于NN的推理:训练一个二分类神经网络进行推理
3. 实验
3.1 数据集和模型
使用四个数据集CIFAR-10/100, STL10-U, TinyIN训练模型。使用ResNet-18作为攻击的backbone。使用Stable Diffusion作为目标模型。
3.2 攻击结果
在各个数据集上的攻击结果如下图所示。对比GAN-leak方法可以看到攻击效果有明显提升。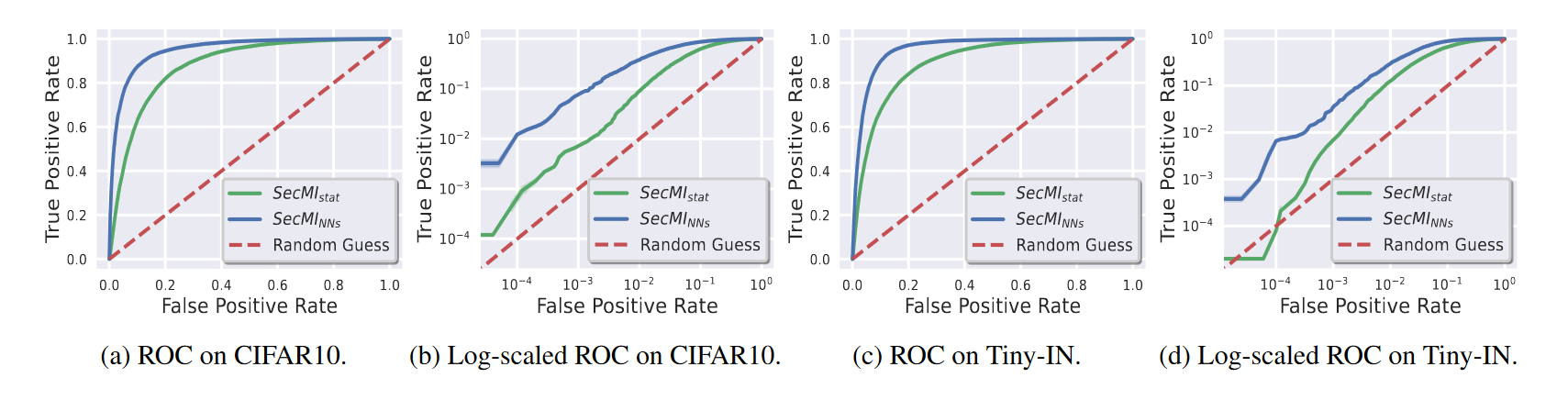
3.3消融实验
总体而言算法表现稳定,方差较小,例如,所有试验中AUC和ASR的方差均不超过0.05。对于时间步 tSECt,尽管我们是基于经验来确定 tSECt_{\text{SEC}}tSEC,但实验表明攻击性能对具体时间步并不敏感。只要 50≤tSEC≤150,攻击就会有效。这一特性在其他实验中也具有良好的泛化性。
查询次数 k会影响查询效率,但实验表明,即使只有3次查询,SecMI仍能实现显著的攻击效果。在权重调整(WA)方面,一个有趣的现象是,WA会带来一定程度的隐私泄露,这提醒研究社区在选择训练协议时需要更加谨慎。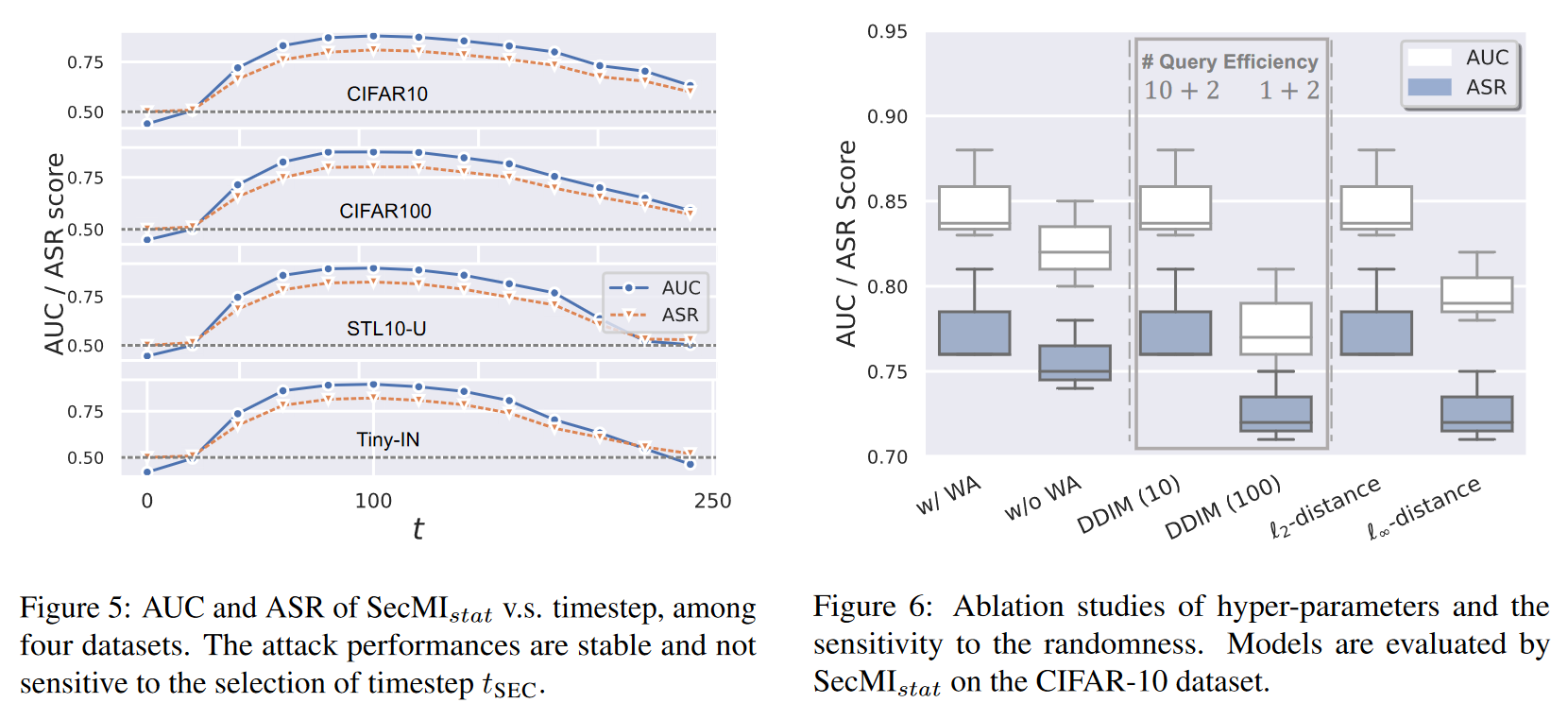
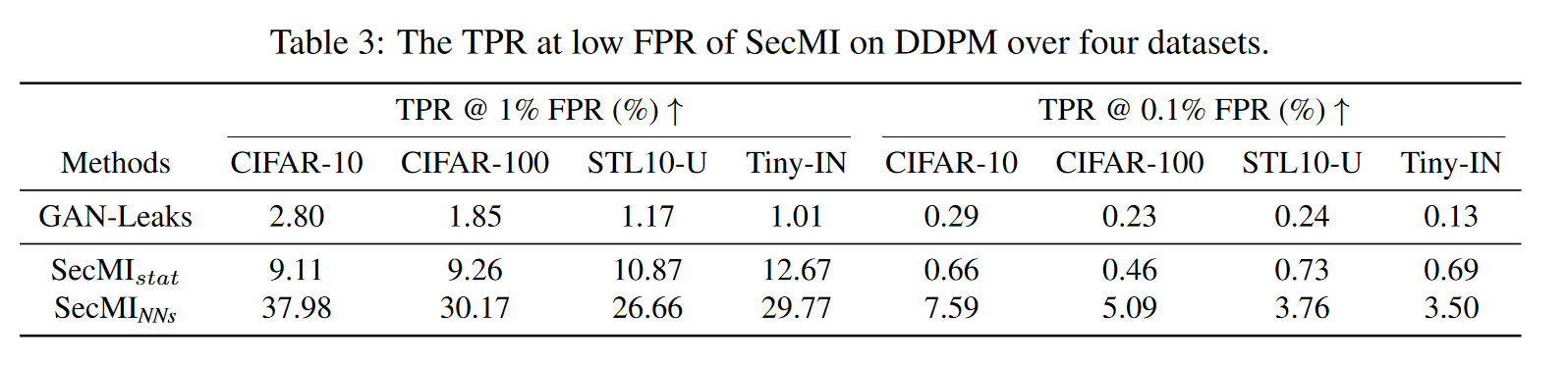
下表展示了该攻击面对不同防御方法时的效果。攻击的指标都出现了不同程度的下降。