论文题目:A Survey of Safety on Large Vision-Language Models: Attacks, Defenses and Evaluations
发表时间: 2025
发表期刊/会议:
论文作者:Ye, Mang; Rong, Xuankun; Huang, Wenke; Du, Bo; Yu, Nenghai; Tao, Dacheng
1. 内容简介
这篇文章是一篇关于视觉-语言多模态模型的安全综述。主要对现有攻击、防御和评估方法进行分类。这篇笔记主要记录攻击和防御部分。
2. 主要内容
2.1 文章贡献
- 系统化分析LVLM安全性:论文整合了攻击、防御和评估这三个相互关联的方面,对LVLM安全性进行了全面、系统的分析。单独研究攻击或防御无法全面刻画LVLM的安全态势,而论文的研究结合了这些关键要素,提供了对LVLM漏洞及其缓解策略的整体理解。
- 构建通用安全分类框架:基于LVLM生命周期分析,论文们提出了一个通用分类框架,按照推理阶段(Inference Phase)和训练阶段(Training Phase)对安全相关研究进行分类,并进一步细分子类别,以提供更细粒度的理解。对于每项研究,论文深入探讨其方法论与贡献,全面剖析当前LVLM安全领域的研究格局。
- 最新LVLM安全性评估与未来研究方向:论文对最新的LVLM——Deepseek Janus-Pro进行了安全评估,并探讨未来研究路径,提供深刻见解和战略性建议。这些指导意见将有助于研究社区进一步提升LVLM的安全性与稳健性,确保其在关键任务应用中的安全可靠部署。
2.2 背景
大视觉语言模型:大型语言模型(LLMs)的发展已成为人工智能领域的基石,彻底改变了机器对人类语言的理解与生成方式。代表性的 LLM 包括 OpenAI 的 GPT-4、Google 的 PaLM、Meta 的 LLaMA 以及 Vicuna,这些模型在自然语言理解与生成方面展现出了卓越的能力。
为了拓展 LLM 的应用范围,研究者通常将其与视觉组件集成,从而发展出大型视觉-语言模型(LVLMs)。LVLMs 通过视觉特征提取器对图像进行编码,并利用连接模块将视觉标记投影到 LLM 的词嵌入空间,使得模型能够联合处理文本和视觉输入。这一多模态集成弥合了视觉与语言之间的鸿沟,为各个领域的高级应用铺平了道路。
LVLMs 面临的挑战:尽管 LVLMs 展现出了卓越的能力,但它们仍面临多个关键挑战:
- 可扩展性(Scalability):多模态数据的集成显著增加了训练和推理阶段的计算需求,带来计算成本和能耗问题。
- 对抗性鲁棒性(Robustness to Adversarial Inputs):多模态环境中的对抗攻击能够利用文本和视觉输入之间的交互,导致模型生成意外或不安全的输出。
- 偏见与公平性(Bias and Fairness):LVLMs 可能会继承训练数据中的偏见,在敏感场景下产生不公平或有害的结果。
- 安全性与对齐(Safety and Alignment):由于训练数据的不足或模型在多模态查询上的理解缺陷,LVLMs 仍然容易生成有害或误导性内容,安全性和对齐性问题仍需持续优化。
攻击者能力:可以按照按照攻击者的知识集合$\mathcal K$对攻击进行分类。该集合包括模型参数$\theta$,模型架构$\mathcal A_\theta$,梯度$\nabla_\theta\mathcal L$,输入$x$和输出$y$。按照这些信息可以大致把攻击者能力分为三类:
- 白盒能力:可以知道所有知识。
- 灰盒能力:可以知道部分内部信息,如模型架构,但是缺少参数和梯度信息。
- 黑盒能力:只能知道输入和输出。
攻击目标:分为有目标、无目标、越狱攻击
- 有目标攻击:将任意输入x的输出变为指定的y
- 无目标攻击:改变任意x的输出为其他值
- 越狱攻击:绕过模型安全机制,使其输出不安全的内容
攻击策略:按照攻击策略划分可以分为如下的五类:
- 基于扰动的攻击:(类似对抗样本)在输入中添加难以察觉的扰动,使模型产生错误输出
- 基于迁移的攻击:利用对抗样本的迁移性进行攻击
- 基于提示的攻击:通过操纵输入提示来误导模型
- 基于投毒的攻击:训练数据中注入恶意数据,影响模型的学习过程
- 基于触发器的攻击:训练数据中嵌入特定后门,在推理过程中发现后门时会导致模型按照预设方式进行变化
2.3 攻击方法
针对视觉语言模型的攻击可以分为推理时攻击和训练时攻击。
推理时攻击:通过精心设计的恶意输入来完成攻击。分为黑盒、白盒、灰盒。总结如下: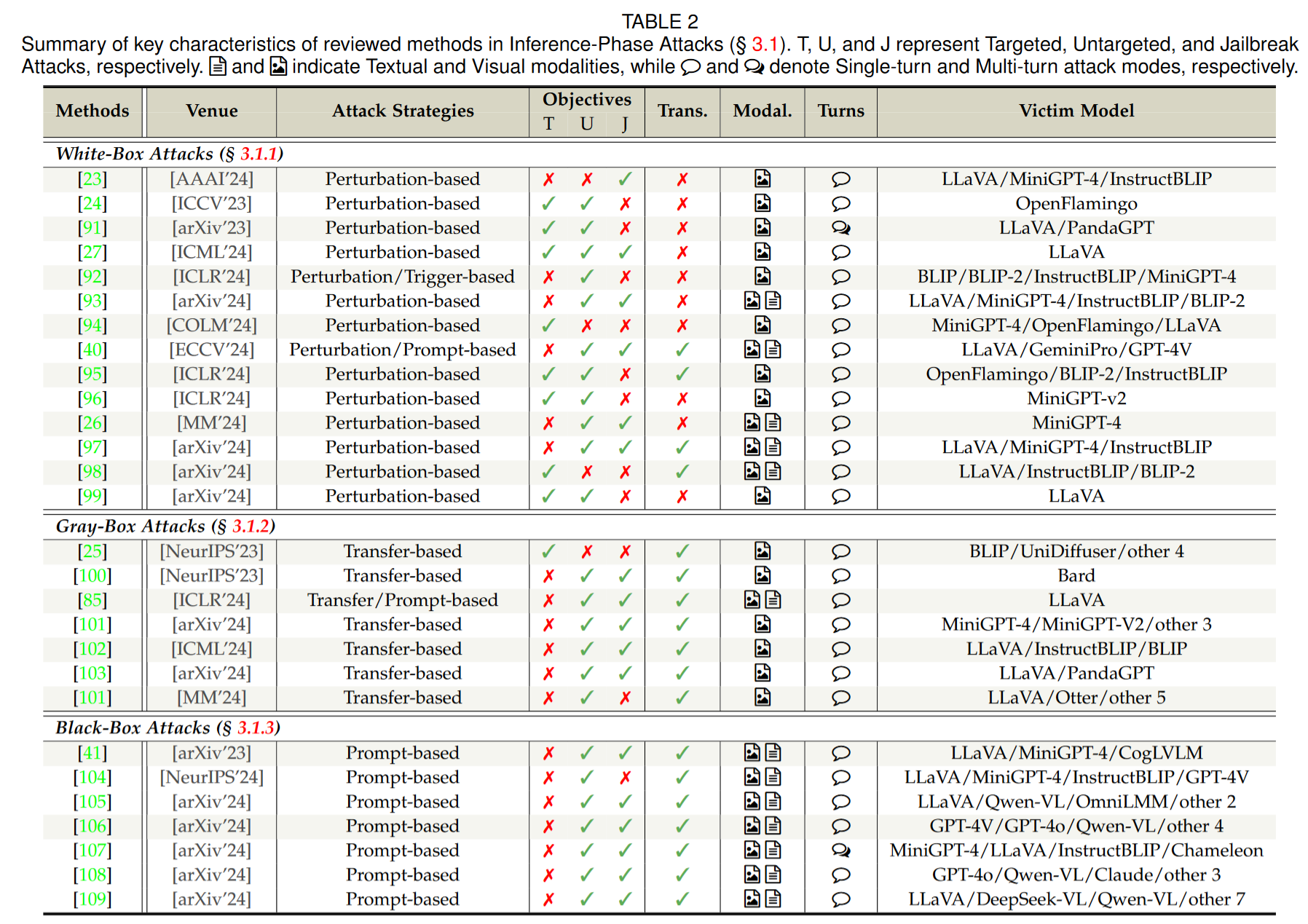
训练时攻击: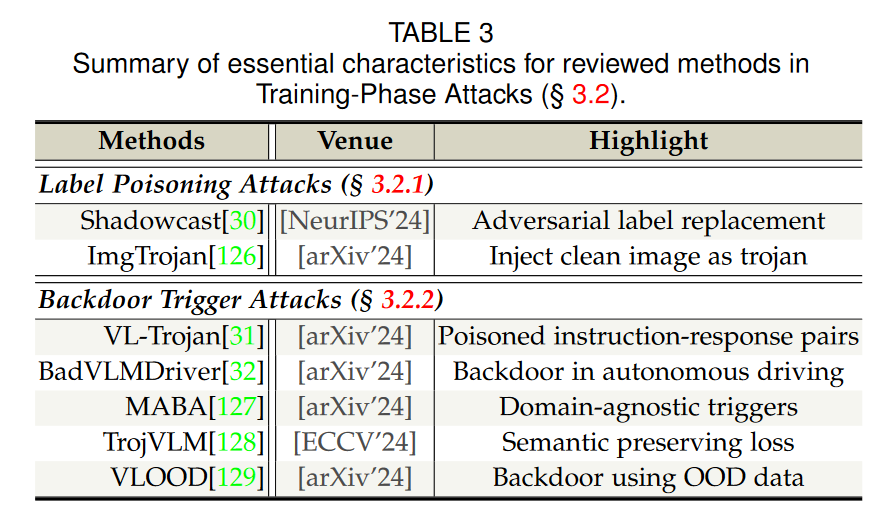
2.4 防御方法
推理时防御: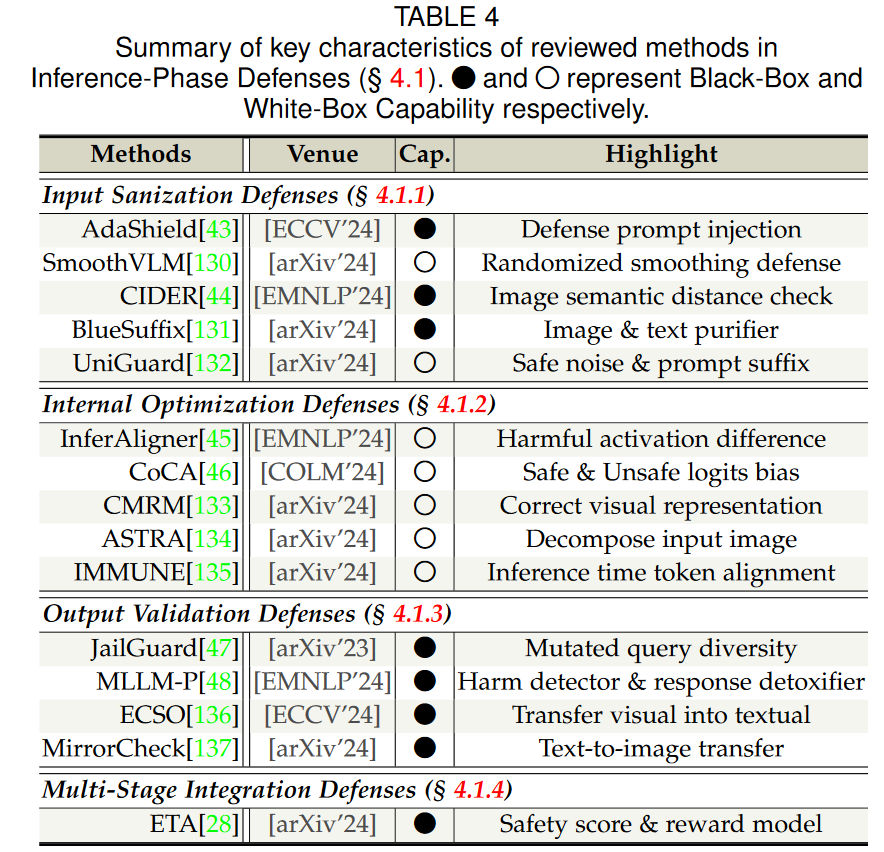
训练时防御: